


The InfrOS Blog

How I Built a FinOps Cost Optimization Agent on Amazon Bedrock AgentCore to Cut a Company’s AWS Bill

The Business Challenge
A CIO at a large enterprise reached out with a problem I hear often. Their cloud costs were climbing, but they had no budget to hire a dedicated FinOps team or to pay for one of the expensive SaaS cost-management platforms on the market.
Their engineering, cloud operations, and SRE teams needed a simple way to understand where the money was going, spot optimization opportunities, and get clear recommendations, without anyone having to become a FinOps specialist first. The request was direct:
“Can we build an AI assistant that understands our cloud environment, answers questions about our costs in plain language, and tells us how to reduce spending whenever the teams need it?”
That question is what led me to build a Cost Optimization Agent on AWS: a conversational interface that lets any engineer ask about cloud spend, see where it is going, and get specific actions to bring it down.
What I Built
The agent answers questions like “Are my costs higher than usual this month?” or “How can I reduce my Lambda spend?” and replies with an analysis and concrete recommendations. It is a single-agent design built from a few clear parts:
- Claude Sonnet, served through Amazon Bedrock: the model that interprets the question and reasons over the cost data it gets back.
- Amazon Bedrock AgentCore Runtime: hosts the agent in production and runs its reasoning-and-tool-selection loop, with auto-scaling, session isolation, and monitoring handled for me.
- Amazon Bedrock Guardrails: content filtering on both the user input and the model output that keeps conversations inside the FinOps scope, blocks prompt injection, and prevents sensitive data from leaking.
- A set of cost-intelligence tools: each function calls an AWS cost or monitoring API: Cost Explorer, AWS Budgets, Amazon CloudWatch, and AWS Compute Optimizer.
- A production front door and supporting services: Amazon API Gateway and Amazon Cognito for access, Amazon DynamoDB for conversation context, and Amazon SNS for proactive alerts.
I started from the AWS reference implementation in the awslabs agentcore-samples repository, which gave me the core agent and its cost tools. On top of that, InfrOS — a platform that turns requirements in any form (a simple brief, PRD, design doc, TF, HLD diagram etc.) into a priced, validated cloud design — worked out the production architecture around it, adding the pieces a real deployment needs:
- The API Gateway and Cognito front door
- DynamoDB session persistence
- SNS alerting
- Compute Optimizer as a rightsizing source
so the result is a production setup for the customer rather than the sample running as is. The architecture behind it was designed, priced, and validated with InfrOS: it scored the component options across the priority dimensions, priced each one across on-demand, reserved, and spot, then generated the IaC and emulated it in a sandbox, benchmarking the design against the requirements before any of it reached a real AWS account. What would otherwise take an architect weeks came back as a validated, deployable blueprint in a single session.
Architecture
The system runs in us-east-1 and is organized into three layers. The first is the user interaction layer: engineers type their questions into a lightweight web chat UI whose requests arrive through Amazon API Gateway, where Amazon Cognito authenticates the user, Amazon DynamoDB stores and retrieves the conversation context so sessions persist, and Amazon SNS delivers proactive alerts. The second is the agent core: AgentCore Runtime hosts the agent and runs its reasoning loop with the Claude Sonnet model. The third is the cost-intelligence tools, which read from AWS Cost Explorer, AWS Budgets, Amazon CloudWatch, and AWS Compute Optimizer. Rather than running in the organization's management (payer) account, which AWS recommends reserving for org-wide administration rather than for hosting workloads, the agent runs in a dedicated FinOps tooling account. That account is registered as the delegated administrator for AWS Compute Optimizer and is granted scoped, read-only access to organization-wide Cost Explorer data, so it still reads consolidated cost and rightsizing data across every linked account at the organization level without placing an internet-facing workload in the most sensitive account in the organization. AWS Budgets sits in the global scope rather than the Region, since budgets are account wide.
Amazon Bedrock plays two distinct roles in the design, worth separating because the service name is the same in both. One role is Guardrails, filtering the conversation on the way in and on the way out; the other is the model endpoint that serves Claude Sonnet for the agent’s reasoning. Same service, two different jobs.
The agent itself is inexpensive to run about $479 a month against the customer’s $1,500 budget. For a FinOps tool, the interesting detail is that roughly 86% of that ($412) is the Claude Sonnet inference, not the surrounding infrastructure. The model is the cost to watch, which is a point I come back to under future work.
Architecture Decisions
Each part of the design was a deliberate choice that InfrOS evaluated and scored against the priority profiles, and the trade-offs are worth spelling out. Here is the reasoning behind the main ones.
Why AgentCore Runtime?
The customer wanted a production agent, not a prototype, but had no appetite for managing the infrastructure under it. AgentCore Runtime handles auto-scaling, monitoring, and session isolation, and it deploys through the AgentCore starter toolkit, which provisions the runtime, the IAM execution role, and the container image for you. Session isolation matters when several engineers query cost data at once meaning each conversation stays separate. Using AgentCore Runtime, rather than the managed Agents for Amazon Bedrock feature, kept the agent code under our control while still getting managed hosting.
Why Claude Sonnet?
This agent leans on two things: understanding loosely worded cost questions in plain English, and reasoning over structured billing data to produce a clear recommendation with the trade-offs spelled out.
Claude Sonnet is strong at both, and its reliability at choosing the right tool from the catalog kept the loop accurate. Serving it through Amazon Bedrock also kept the model inside the customer’s AWS account and security boundary, which was a requirement.
So why Guardrails?
A cost assistant should only ever talk about costs. Amazon Bedrock Guardrails enforce that topic boundary on both the user input and the model output, block prompt-injection attempts, and stop sensitive data such as access keys or PII from appearing in a response. Putting safety in a managed, declarative layer kept it separate from the agent logic and applied it consistently to every query.
How It Works
A request follows the same numbered path every time, shown end to end below.
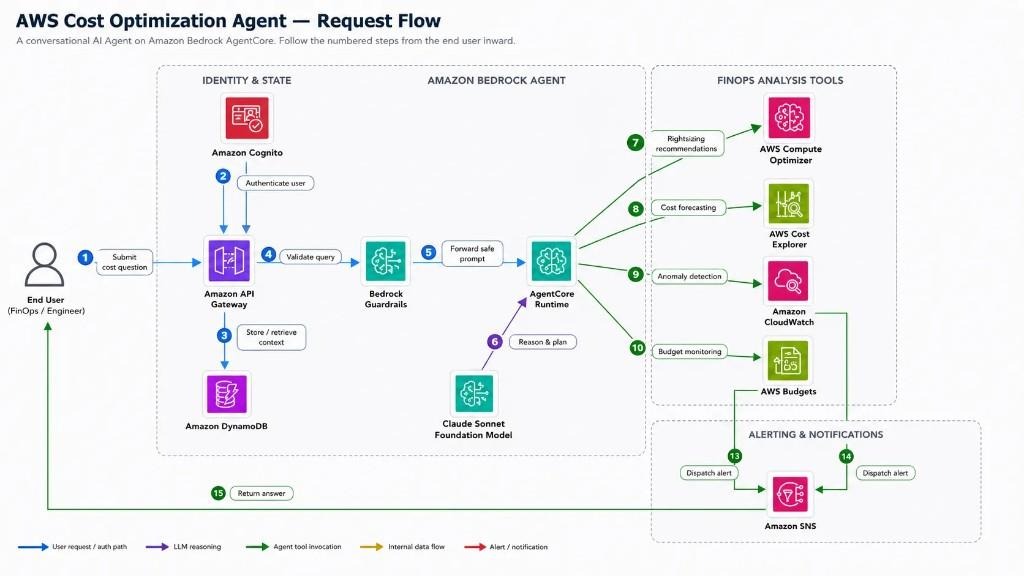
- An engineer submits a cost question through Amazon API Gateway.
- Amazon Cognito authenticates the request.
- DynamoDB stores or retrieves the conversation context, so a follow-up keeps its thread.
- Bedrock Guardrails validate the query, dropping anything off-topic or unsafe.
- The safe prompt is forwarded to AgentCore Runtime, where the agent reasons with the Claude Sonnet foundation model and decides which tools to call:
- Rightsizing recommendations from AWS Compute Optimizer.
- Cost forecasting from AWS Cost Explorer.
- Anomaly detection from Amazon CloudWatch.
- Budget monitoring from AWS Budgets.
- When something needs attention, CloudWatch and Budgets dispatch alerts through Amazon SNS.
- The synthesized answer is returned to the engineer.
The agent does not run a fixed script; the model chooses which tools to call based on the question and may call several before answering.
The four cost tools map directly to AWS APIs:
- Cost Anomaly Detection: unusual spending patterns and spikes, detected with Amazon CloudWatch anomaly detection over cost metrics published from Cost Explorer, with alerts dispatched over SNS.
- Cost Forecasting and Trend Analysis: projected spend and historical trends from AWS Cost Explorer.
- Service Cost Breakdown: spend by service, account, and resource, combining AWS Compute Optimizer rightsizing data with Cost Explorer to flag unused, underutilized, and oversized resources.
- Budget Monitoring and Status: utilization and overrun forecasts from AWS Budgets, with alerts dispatched over SNS.
Infrastructure and Deployment
The agent deploys through the AgentCore starter toolkit, wrapped by the repository’s scripts. After cloning the reference repository and installing dependencies, there are three steps, test locally, deploy, then test the deployed agent against live cost data:
The deploy step calls the starter toolkit, which builds the container image, creates the IAM execution role and ECR repository, and registers the runtime so the agent itself does not need a hand-written infrastructure module. The supporting resources around it (API Gateway, Cognito, DynamoDB, SNS, the Guardrail, and the budget) are defined in Terraform so they are version-controlled and repeatable. The Guardrail, for example, is a short block that also blocks prompt-injection attempts and stops AWS keys from ever appearing in a response:
The Outcome
Before any production rollout, we ran the agent against the customer’s dev and test AWS environment three linked accounts with about $1,012 of spend over the previous 30 days (a window that straddled April and May) to see what it would find. This is the summary it returned:

In a single run it flagged a $115.38 anomaly (EKS extended support, billed April 19–26) and forecast May at $1,023.76, up 13.3% on the full April calendar month of about $904. The $1,012.38 headline is the trailing-30-day total, which runs higher than the April calendar month because that window also caught the EKS spike. Against that roughly $1,012 monthly run rate it identified $369 a month in savings: a 36.5% reduction worth about $4,428 a year.
To be precise, that is spend the agent recommended cutting rather than money already removed, and on a roughly $1,000-a-month sandbox the $4,428-a-year figure is a proof of capability more than an ROI case: at $479 a month the agent would cost more to run than that. What mattered in the pilot was that it surfaced this much on a tiny environment in a single run, as a summary panel alongside its conversational answers. The ROI argument sits with the production rollout below, where the same engine runs against a far larger bill.
On the strength of that pilot the customer moved the agent into production. Within the first few months, the changes the engineers acted on added up to roughly a 12% reduction in the monthly bill. A good part of that came from one early find: an oversized Amazon RDS instance that Compute Optimizer flagged for rightsizing, alongside a handful of EC2 instances the team had spun up for a project and left running for months after they stopped using them.
The agent surfaced both in response to a plain question about where the months spend was going, the kind of thing that usually hides in a billing console until someone goes looking.
Just as important was the change in who could ask cost questions and how fast. Engineers no longer waited on a central team or a paid dashboard; they asked in plain language and got an answer with a recommended action, so cost awareness happened during day to day work instead of in a monthly review. Against the production bill, the roughly $479-a-month agent cost a small fraction of the 12% it helped remove, and it met the original constraint of meaningful FinOps coverage without a dedicated team or a third-party platform, which was the whole reason the CIO called in the first place.
Further Improvements and Architecture Vision
The clearest piece of the architecture vision is memory. Today Amazon DynamoDB stores and retrieves the conversation context, which means I am managing session state, retrieval, and expiry myself. I plan to replace it with Amazon Bedrock AgentCore Memory, which provides short-term memory for the active session and long-term memory that persists across sessions as a native capability of the runtime already hosting the agent. That removes a hand-managed store and lets the platform handle what it is built for the same reasoning behind choosing AgentCore Runtime in the first place. DynamoDB would only stay if there were structured, non-conversational records worth keeping.
Conclusion
The Cost Optimization Agent took a request that usually ends in a hire or a software purchase and answered it with a small, focused build instead. Claude Sonnet through Amazon Bedrock supplies the reasoning, Bedrock Guardrails keep it safe and on topic, AgentCore Runtime hosts it and runs the tool loop, and a set of cost tools connect it to Cost Explorer, Budgets, CloudWatch, and Compute Optimizer with API Gateway, Cognito, DynamoDB, and SNS making it a real deployment. The pattern is reusable: give a model a clear set of narrow tools and a safe runtime, and you can put a useful assistant in front of a problem that used to need a whole team. And the build itself was just as lean: InfrOS turned what would have been weeks of architecture work into a single session, exploring and scoring the options and handing back a priced, validated, IaC-ready design.

9 Best Cloud Governance Tools for Engineering Teams in 2026

Key Takeaways
- Top pick for 2026: InfrOS. It's the only platform that enforces cloud cost governance before resources are provisioned, not after the damage is done.
- Cloud governance has moved from a compliance checkbox to a core engineering discipline. Teams that skip it face spiraling costs, configuration drift, and audit failures.
- The most effective cloud governance tools combine policy enforcement, cost controls, and multi-cloud visibility in a single workflow.
- An IT cost optimization framework built around shift-left governance can reduce cloud waste by up to 43% compared to reactive FinOps approaches.
- Engineering teams get the most value from governance tools that integrate directly into IaC pipelines and CI/CD workflows, not standalone dashboards.
Why Engineering Teams Can't Skip Cloud Governance in 2026
Cloud environments don't stay clean on their own. A team of five engineers can spin up hundreds of resources across AWS, Azure, and GCP in a single sprint. Without consistent guardrails, what starts as a well-structured environment becomes a tangle of untagged instances, orphaned storage volumes, over-permissive IAM roles, and unexplained line items on the monthly bill.
This is the core problem cloud governance tools exist to solve. And in 2026, the stakes are higher than ever.
Three forces are making governance non-negotiable. First, multi-cloud is now the default. Most engineering teams operate across at least two cloud providers, and maintaining consistent policies across different control planes, AWS Organizations, Azure Policy, GCP Organization Policies, requires tooling, not manual effort. Second, AI workloads are inflating cloud spend faster than any previous technology wave. GPU compute, large-scale inference, and data pipeline infrastructure don't forgive misconfigured autoscaling or missing budget alerts. Third, compliance requirements are getting stricter. GDPR, SOC 2, HIPAA, and industry-specific frameworks all demand audit trails, encryption enforcement, and access controls that only systematic governance can reliably deliver.
The engineering teams that treat governance as a one-time setup task will keep paying for it in post-deployment rework, surprise bills, and audit findings. The ones embedding governance tools into their daily workflows are shipping faster and spending less.
What Makes a Cloud Governance Tool Enterprise-Ready
Not every tool that calls itself a governance platform is actually built for engineering teams operating at scale. Here's what separates enterprise-ready cloud governance tools from the rest.
Automatic policy enforcement. The tool must enforce rules, not just report on violations. If a misconfigured resource can reach production because the policy engine only flags it after the fact, it's a monitoring tool, not a governance tool. Look for enforcement at the IaC level, in CI/CD pipelines, or at the cloud API layer before provisioning completes.
Multi-cloud support across AWS, Azure, and GCP. Single-cloud governance tools create blind spots the moment your team deploys anything outside that provider. A genuine enterprise solution applies consistent policies and visibility across all three major clouds from a unified control plane.
Granular cost alerting and budget guardrails. Cloud cost governance requires more than a monthly budget threshold. Effective tools provide per-service, per-team, and per-environment budget limits with real-time anomaly detection, so cost spikes surface within hours, not at month-end.
Enforced tagging standards. Tagging is the foundation of cost attribution, access control, and cleanup automation. An enterprise-ready tool makes tagging non-negotiable, resources that don't meet tagging requirements fail validation before they're deployed.
Drift detection. Infrastructure drifts from its intended state constantly. Governance tools need to continuously compare running resources against the declared baseline and surface deviations before they create security gaps or compliance failures.
Together, these capabilities create the foundation of an IT cost optimization framework that scales with engineering teams across AWS, Azure, and GCP. When governance is embedded early, teams can control spend, maintain compliance, and reduce operational overhead without slowing down deployments
9 Best Cloud Governance Tools for Engineering Teams in 2026
The tools below were selected based on depth of policy enforcement, multi-cloud coverage, IaC integration, and real-world impact on cloud cost governance. Each has a distinct strength and a clear use case. InfrOS is listed first because it's the only platform that addresses governance at the design stage rather than after deployment.
1. InfrOS
InfrOS approaches cloud governance from the direction most tools ignore: the design phase. Before a single resource is provisioned, InfrOS validates architecture candidates against cost targets, compliance policies, security requirements, and performance benchmarks, in a sandboxed emulation environment.
Key features:
- Pre-deployment architecture emulation and policy validation across AWS, Azure, and GCP
- Automated cost benchmarking with deterministic results before IaC is applied
- Production-ready Terraform generation with embedded compliance guardrails
- Continuous lifecycle optimization and drift detection after deployment
- Runtime feedback loop that feeds real-world performance data back into the next design cycle
Where most governance tools catch problems that already exist in your environment, InfrOS prevents them from being introduced in the first place. For teams building new infrastructure or migrating workloads, that shift-left approach is what drives the 43% average infrastructure cost reduction seen across InfrOS deployments.
2. AWS Control Tower + Service Control Policies (SCPs)
AWS Control Tower is the native governance layer for organizations running multi-account AWS environments. It sets up a landing zone with built-in guardrails and uses Service Control Policies to restrict what member accounts can and cannot do.
Key features:
- Centralized governance across AWS Organizations
- Pre-built guardrails for security, compliance, and operational baselines
- Account vending with consistent baseline configurations
- Integration with AWS Config for continuous compliance monitoring
Control Tower is the right choice for AWS-first organizations that need to govern a large number of accounts consistently. Its limitations show in multi-cloud environments, where it has no visibility outside AWS.
3. Azure Policy + Microsoft Defender for Cloud
Azure Policy lets teams define and enforce rules across Azure subscriptions and management groups. Combined with Microsoft Defender for Cloud, it provides continuous security posture assessment alongside policy enforcement.
Key features:
- Policy assignments at the subscription and management group level
- Built-in policy definitions for compliance frameworks including CIS, NIST, and PCI DSS
- Automatic remediation tasks for non-compliant resources
- Regulatory compliance dashboard with audit-ready reporting
For organizations heavily invested in Azure, this combination delivers deep governance coverage without additional tooling. Multi-cloud teams will need supplementary solutions for AWS and GCP workloads.
4. HashiCorp Sentinel (Terraform Cloud / Enterprise)
Sentinel is HashiCorp's policy-as-code framework built directly into Terraform Cloud and Terraform Enterprise. Policies are written in Sentinel's own language and evaluated against Terraform plans before apply runs, meaning violations are blocked before any infrastructure changes.
Key features:
- Policy evaluation at plan time, before any resource is provisioned
- Fine-grained enforcement modes: advisory, soft-mandatory, and hard-mandatory
- Native integration with Terraform's plan output for detailed violation context
- Support for cost estimation policies alongside security and compliance rules
Sentinel is purpose-built for teams that standardize on Terraform. It's one of the strongest options for embedding an IT cost optimization framework directly into IaC workflows, because policies run as part of the normal deployment pipeline.
5. Open Policy Agent (OPA) + Conftest
OPA is an open-source, general-purpose policy engine. Combined with Conftest, a wrapper that makes OPA easy to use against Terraform plans, Kubernetes manifests, and Dockerfile configs, it becomes a powerful, flexible governance layer that works across any CI/CD pipeline.
Key features:
- Policy written in Rego, a declarative query language designed for structured data
- Works against Terraform plans, Kubernetes YAML, Helm charts, and Dockerfiles
- Lightweight and CI/CD native, runs as a step in GitHub Actions, GitLab CI, or any pipeline
- Active open-source community with a large library of reusable policy examples
OPA is the right choice for teams that want maximum flexibility and don't mind writing their own policies. It requires more upfront investment than commercial solutions but has no licensing cost and integrates with almost everything.
6. Cloud Custodian
Cloud Custodian is an open-source policy engine from Capital One, designed for automated resource management and compliance across AWS, Azure, and GCP. It's particularly strong for cleanup automation, finding and acting on idle, orphaned, or non-compliant resources at scale.
Key features:
- Policy library covering hundreds of resource types across three major clouds
- Real-time event-driven enforcement via CloudWatch Events, Azure Event Grid, and GCP Pub/Sub
- Automated remediation actions: stop, delete, tag, notify, or quarantine
- Scheduling for off-hours workload management and cost reduction
Cloud Custodian fills a gap that policy-as-code frameworks often miss: the ongoing management of what's already running. It's a strong complement to design-time governance tools like InfrOS or Sentinel. See how it fits into a broader cloud cost management strategy.
7. Wiz
Wiz is a cloud security platform that gives engineering and security teams deep visibility into risk across multi-cloud environments. It's built around an inventory and relationship graph that maps every resource, identity, network path, and vulnerability in a unified view.
Key features:
- Agentless scanning across AWS, Azure, GCP, and Kubernetes
- Security graph that surfaces attack paths, not just isolated findings
- Built-in compliance frameworks with automated evidence collection
- Integration with CI/CD pipelines for shift-left security scanning
Wiz is the strongest option for teams where security posture and compliance evidence are the primary governance concern. It's not a cost governance tool, but its policy and compliance capabilities are enterprise-grade.
8. Spot by NetApp (CloudCheckr)
Spot by NetApp, incorporating the CloudCheckr platform, provides multi-cloud governance with a focus on cost visibility, compliance reporting, and resource optimization. It's widely used in managed service provider (MSP) and enterprise environments where accountability across business units matters.
Key features:
- Multi-cloud cost allocation with showback and chargeback reporting
- Over 500 best-practice checks across security, cost, and availability
- Reserved instance and savings plan management with utilization tracking
- Role-based access control for multi-team and multi-client environments
Spot is best suited for organizations that need governance reporting across complex account structures, particularly where different teams or clients are billed separately for their cloud usage.
9. Checkov (by Bridgecrew / Prisma Cloud)
Checkov is an open-source static analysis tool that scans IaC files, Terraform, CloudFormation, Kubernetes manifests, ARM templates, and more, before they're deployed. It's fast, developer-friendly, and integrates into any CI/CD pipeline in minutes.
Key features:
- Over 1,000 built-in checks for security and compliance across all major IaC frameworks
- Supports custom policies using Python or YAML
- Native integration with GitHub, GitLab, and Bitbucket for PR-level feedback
- Graph-based analysis to catch complex misconfigurations that simple rules miss
Checkov is the entry point for many engineering teams starting with cloud governance. It's free, fast to set up, and provides immediate feedback on common issues like public storage buckets, missing encryption, and overly permissive IAM policies. Pair it with a runtime governance tool for complete coverage across the infrastructure lifecycle.
How Cloud Governance Tools Support Cost Control and Compliance
Cloud cost governance and compliance aren't separate concerns, they run on the same underlying infrastructure: consistent policies, enforced tagging, and budget guardrails applied systematically across every environment.
In practice, cloud cost governance works in layers. The first layer is prevention: catching expensive or non-compliant configurations before they're deployed. This is where InfrOS, Sentinel, and Checkov operate, evaluating IaC and architecture designs against cost targets and policy rules before a resource ever runs. The second layer is enforcement: ensuring running environments stay within budget and policy bounds. Tools like Cloud Custodian, AWS Config, and Azure Policy handle this by continuously checking live resources and triggering automated remediation when violations occur. The third layer is visibility: giving engineering, finance, and leadership teams a shared view of where money is going and why. This is where cost allocation tools with tagging enforcement and showback reporting add value.
An effective IT cost optimization framework connects all three layers. It starts with design-time validation to prevent structural waste from entering production in the first place. It enforces tagging standards so every resource can be attributed to a team, environment, and business unit from day one. It sets budget thresholds at the service, account, and team level, with real-time anomaly alerts rather than monthly surprises. And it creates a feedback loop, runtime data flows back into the next architecture review, so the environment continuously improves rather than drifting toward waste.
The most common failure mode teams encounter is treating governance as a reporting exercise. Dashboards that show you what you spent last month are useful context. Policies that prevent overspending from happening in the first place are what move the needle. The best cloud cost optimization tools share a common characteristic: they make cost a constraint at design time, not a metric to be reviewed after the fact.
For compliance, the same principle applies. Running an audit after deployment to check whether encryption is enabled or public access is blocked is better than nothing. But policy enforcement in IaC pipelines, blocking non-compliant configurations from being merged and deployed, eliminates entire categories of audit findings before they occur.
FAQ
What is the difference between cloud governance and cloud management?
Cloud governance defines the rules, policies, and standards that determine how cloud resources should be used, who can deploy, what configurations are allowed, how costs are attributed. Cloud management is the operational work of running environments within those rules: provisioning, monitoring, scaling, and incident response. Governance sets the guardrails; management drives within them.
How do cloud governance tools work with IaC pipelines?
Most modern governance tools integrate as a step in CI/CD pipelines, evaluating Terraform plans, CloudFormation templates, or Kubernetes manifests before they're applied. Tools like Sentinel, OPA, and Checkov block non-compliant changes from merging or deploying. This shifts enforcement left, so violations are caught during code review rather than in production.
Can one tool enforce policy across AWS, Azure, and GCP?
Yes, tools like InfrOS, Cloud Custodian, OPA, and Wiz all operate across multiple cloud providers from a single control plane. Native provider tools (AWS Control Tower, Azure Policy, GCP Org Policies) are powerful within their own ecosystem but require separate configuration for each provider. Multi-cloud governance is best handled by platform-agnostic tools with native integrations across all three.
How do these tools help reduce cloud spending?
Cloud governance tools reduce spend by preventing waste before deployment and continuously enforcing policies after resources go live. They catch overprovisioned services, missing budget guardrails, and untagged infrastructure early, then automate cleanup and alerts so teams spend less time reacting to unnecessary cloud costs.
.jpg)
Enterprise Architecture Maturity Model: Stages, Criteria, and What to Do at Each Level
Key Takeaways
- An enterprise architecture maturity model gives organizations a structured way to assess how well their IT systems support business goals, and a clear path to improve.
- Most companies sit at Stage 2 or 3: they have some architecture documentation and standards, but decisions are still largely reactive, inconsistent, or siloed.
- Each maturity stage demands different actions. Describing the stages without prescribing what to do next is where most guides fall short.
- Cloud architecture decisions should be driven by your maturity level, teams at lower stages need to consolidate and standardize before pursuing complex multi-cloud strategies.
- InfrOS helps engineering teams act on their maturity stage by providing validated, pre-deployment architecture design, so every infrastructure decision is grounded in proven requirements rather than educated guesses.
What Is an Enterprise Architecture Maturity Model
An enterprise architecture maturity model is a structured way to assess how well IT systems and architecture decisions support business goals, and what needs to improve over time.
Organizations don’t manage technology with the same level of consistency or strategic intent. Some make infrastructure decisions reactively, one project at a time. Others operate with documented, governed architecture that guides every major investment. A maturity model maps that progression into defined stages.
Companies use it because “improve IT” is too vague to act on. A maturity model creates a clear baseline: where you are now, what gaps exist, and what actions move you forward. The result is stronger investment planning, better alignment between engineering and leadership, and a more practical roadmap for IT infrastructure transformation.
The 5 Stages of Enterprise Architecture Maturity and What to Do at Each Level
Maturity models vary in their exact terminology, but the underlying progression is consistent. Organizations move from ad hoc, undocumented decisions toward managed, strategically integrated architecture. Here are the five stages, what each one looks like from the inside, and, critically, what to actually do at each level.
Stage 1, Initial: What it looks like + what to do next
At Stage 1, there is no formal architecture practice. Technology decisions are made by individual teams or project managers without coordination. Infrastructure is built to solve immediate problems. Documentation, when it exists, lives in someone's head or a shared drive that no one maintains. Security and compliance are handled reactively. Costs are difficult to explain because no one has full visibility into what's running or why.
This isn't a failure state, it's a starting point that most organizations pass through. The problem is staying here too long.
What to do next: The priority at Stage 1 is visibility, not transformation. Start by taking inventory. Document what systems exist, what they do, who owns them, and what they cost. Don't attempt to redesign anything yet. Establish a small, cross-functional group responsible for architecture decisions, even informally. The goal is to stop making undocumented choices and start building a shared picture of the current state.
Stage 2, Developing: What it looks like + what to do next
At Stage 2, architecture documentation exists but isn't consistently maintained or used. Some teams follow standards; others don't. There may be an architecture function, a team or a few senior engineers with that title, but their influence on day-to-day decisions is limited. Cloud adoption is underway but fragmented: different business units use different providers, different tools, and different conventions. Costs are tracked at the account level but not attributed to teams, services, or business outcomes.
This is where a large proportion of mid-size enterprises sit. The documentation and the intent are there, but enterprise architecture integration into actual decision-making is weak.
What to do next: The priority at Stage 2 is standardization. Define and enforce a baseline set of conventions: naming standards, tagging requirements, approved cloud services, identity and access patterns. These don't need to be perfect, they need to be agreed upon and applied consistently. Introduce architecture review as a lightweight step in project intake, not a gate that slows teams down, but a checkpoint that surfaces alignment issues early. Begin connecting infrastructure spend to business units so cost ownership becomes visible.
Stage 3, Defined: What it looks like + what to do next
At Stage 3, the architecture function has real influence. Standards exist, are documented, and are largely followed. Architecture reviews happen before significant projects begin. There is a current-state inventory that's reasonably accurate. Cloud enterprise architecture decisions are made with awareness of the broader environment rather than in isolation. Compliance and security requirements are mapped to infrastructure, though enforcement may still be partially manual.
The main gap at Stage 3 is execution. Architecture is documented, but environments still drift as teams move quickly and changes bypass review.
What to do next: The priority at Stage 3 is closing the gap between design and reality. This means investing in tooling that detects drift, enforces policy in pipelines rather than after deployment, and connects architecture decisions to infrastructure code. Shift architecture review earlier, into the design and planning phase, not just the approval phase. Begin measuring architecture outcomes: deployment frequency, incident rates tied to architecture decisions, cost per service. These metrics build the business case for the next stage of investment.
Stage 4, Managed: What it looks like + what to do next
At Stage 4, architecture is quantitatively managed. Decisions are informed by data: utilization metrics, cost-per-unit economics, performance benchmarks, compliance dashboards. The gap between intended and actual architecture is tracked and systematically reduced. Enterprise architecture integration is real, business strategy and technology strategy are explicitly connected, and architecture decisions reference business outcomes rather than just technical preferences.
Cloud architecture at this stage is intentional. Multi-cloud or hybrid environments are governed deliberately, and infrastructure transformation projects begin with validated target architectures.
What to do next: The priority at Stage 4 is continuous improvement and automation. Architecture governance should be embedded in CI/CD pipelines so enforcement is automatic rather than manual. Begin building predictive capability: using cost and performance data to model the impact of architectural changes before they're made. Platforms like InfrOS operate in this mode, generating validated, benchmarked architecture designs before deployment so that every infrastructure change has a proven outcome attached to it. Teams at Stage 4 are ready to use this kind of tooling at full value.
Stage 5, Optimizing: What it looks like + what to do next
At Stage 5, architecture is self-improving. The organization treats its IT environment as a continuously evolving system: runtime feedback loops into the next design cycle, cost and performance data drives automated optimization recommendations, and architecture decisions are made with quantified confidence rather than professional judgment alone. Business and technology planning are genuinely integrated, the architecture roadmap and the business strategy are produced together, not reconciled after the fact.
Very few organizations operate consistently at Stage 5. It’s best treated as a direction rather than a fixed destination.
What to do next: The work at Stage 5 is sustaining and scaling. Governance models that work for a 200-person engineering team may not hold at 2,000. Architecture practices need to evolve as the organization grows, acquires companies, or expands into new markets. Invest in architecture enablement, tools, documentation, and training that let teams self-serve within well-defined guardrails rather than routing everything through a central review function. The goal is an architecture practice that scales with the business without becoming a bottleneck.
The Criteria Used to Assess EA Maturity
Moving from a self-assessment to a reliable maturity score requires evaluating specific dimensions of the architecture practice. These are the areas that consistently distinguish lower-maturity organizations from higher-maturity ones.
Technology use. How systematically is technology selected, managed, and retired? Low-maturity organizations accumulate tools without strategic intent. High-maturity organizations maintain a rationalized technology portfolio, make explicit decisions about approved services, and decommission what no longer serves a purpose.
Data quality and currency. Architecture documentation is only useful if it reflects reality. Assess how often your architecture inventory is updated, who owns it, and how closely it matches what's actually running in production. Stale documentation is a Stage 2 characteristic; continuously maintained, system-integrated inventories are Stage 4.
Team participation. Architecture maturity is not a property of the architecture team alone, it's a property of how the entire engineering organization makes decisions. How often are architecture considerations surfaced in team-level planning? How much do product and engineering teams understand about the architecture standards that apply to their work?
How architecture decisions are shared. At low maturity, architecture decisions live in documents that few people read. At high maturity, they're embedded in tools, pipelines, and approved patterns that developers encounter naturally as they work. Decision visibility and accessibility are strong signals of where an organization sits on the scale.
Cost alignment. Can your organization trace infrastructure spend to specific business outcomes? The ability to answer questions like "what does it cost us to serve one customer" or "what did this architectural change cost us in production" is a reliable indicator of maturity. Organizations without tagging standards, cost attribution, or unit economics tracking tend to cluster at Stages 1–2.
Security and compliance. How are security requirements enforced, through manual review, automated policy checks, or by design? At lower maturity, security is a layer applied after the fact. At higher maturity, it's a constraint incorporated at the design stage, validated before deployment, and continuously monitored in production.
How EA Maturity Connects to Cloud Architecture and IT Transformation
Your position on the maturity scale has direct, practical consequences for how you should approach cloud enterprise architecture decisions and IT infrastructure transformation.
Low-maturity teams, Stage 1 and 2, are operating reactively. Architecture decisions get made in the context of individual projects, without visibility into the broader environment. When these teams attempt complex cloud migrations or multi-cloud strategies, they consistently encounter the same problems: inconsistent environments, cost overruns, compliance gaps, and rework. The issue isn't cloud strategy, it's that the foundational architecture practice isn't ready to support it. Attempting an IT infrastructure transformation before reaching at least Stage 3 is a predictable source of expensive failure.
Mid-maturity teams, Stage 3, have the standards and documentation to support cloud enterprise architecture decisions, but they often lack the enforcement mechanisms to keep those decisions consistent across teams and over time. Cloud environments at this stage tend to drift: what was designed and what's running diverge as teams move fast and bypass review processes. The transformation work at Stage 3 is connecting architecture intent to actual infrastructure, through policy-as-code, IaC validation, and tooling that surfaces drift automatically.
High-maturity teams, Stage 4 and 5, design first and deploy with confidence. This is where enterprise architecture integration becomes a genuine competitive advantage rather than an overhead cost. Architecture decisions are validated before deployment, grounded in benchmarked data rather than estimates, and connected to measurable business outcomes. IT infrastructure transformation at this level is predictable: timelines hold, costs come in as projected, and post-deployment surprises are the exception rather than the rule.
InfrOS is built for teams making this shift. By emulating architecture candidates in a sandboxed environment before any resources are provisioned, it gives engineering teams the validated design foundation that Stage 4 and 5 maturity requires, and accelerates the path for Stage 3 teams ready to close the gap between design and deployment. Whether you're planning a cloud migration or building toward scalable cloud infrastructure, the architecture decisions you make before deployment determine the outcomes you get in production.
Organizations that treat architecture as a design discipline, not just documentation, typically spend less, deploy faster, and avoid more post-deployment remediation. Maturity measures how consistently they can do that.
FAQ
What is the difference between an EA maturity model and an EA framework?
A framework such as TOGAF or Zachman outlines how an enterprise architecture practice is structured and documented. A maturity model measures how consistently those practices are applied and how developed they are. Frameworks define the approach; maturity models show how effectively that approach is working.
How long does it take to move from one maturity stage to the next?
Most organizations move between maturity stages in six to twenty-four months depending on size, leadership support, and available tooling. Standardizing processes usually happens faster. Moving into higher maturity levels takes longer because it often requires automation, stronger governance, and closer alignment between architecture and business planning.
How does EA maturity affect cloud architecture decisions?
At lower maturity levels, cloud architecture decisions are usually reactive and disconnected across teams. At higher maturity levels, decisions are planned against documented standards, validated before deployment, and tied to measurable business outcomes. That leads to more predictable costs, stronger governance, and fewer infrastructure changes after launch.
Which model works best for companies undergoing IT infrastructure transformation?
For teams in active IT infrastructure transformation, models such as the US government Architecture Maturity Model or Gartner ITScore provide useful structure. The most important factor is consistency: assess your current state, identify the biggest gaps, and use that information to prioritize architecture decisions before major infrastructure investments.
The Shift-Left Revolution in Cloud Infrastructure: Design It Right Before You Deploy It

The Shift-Left Revolution in Cloud Infrastructure: Design It Right Before You Deploy It
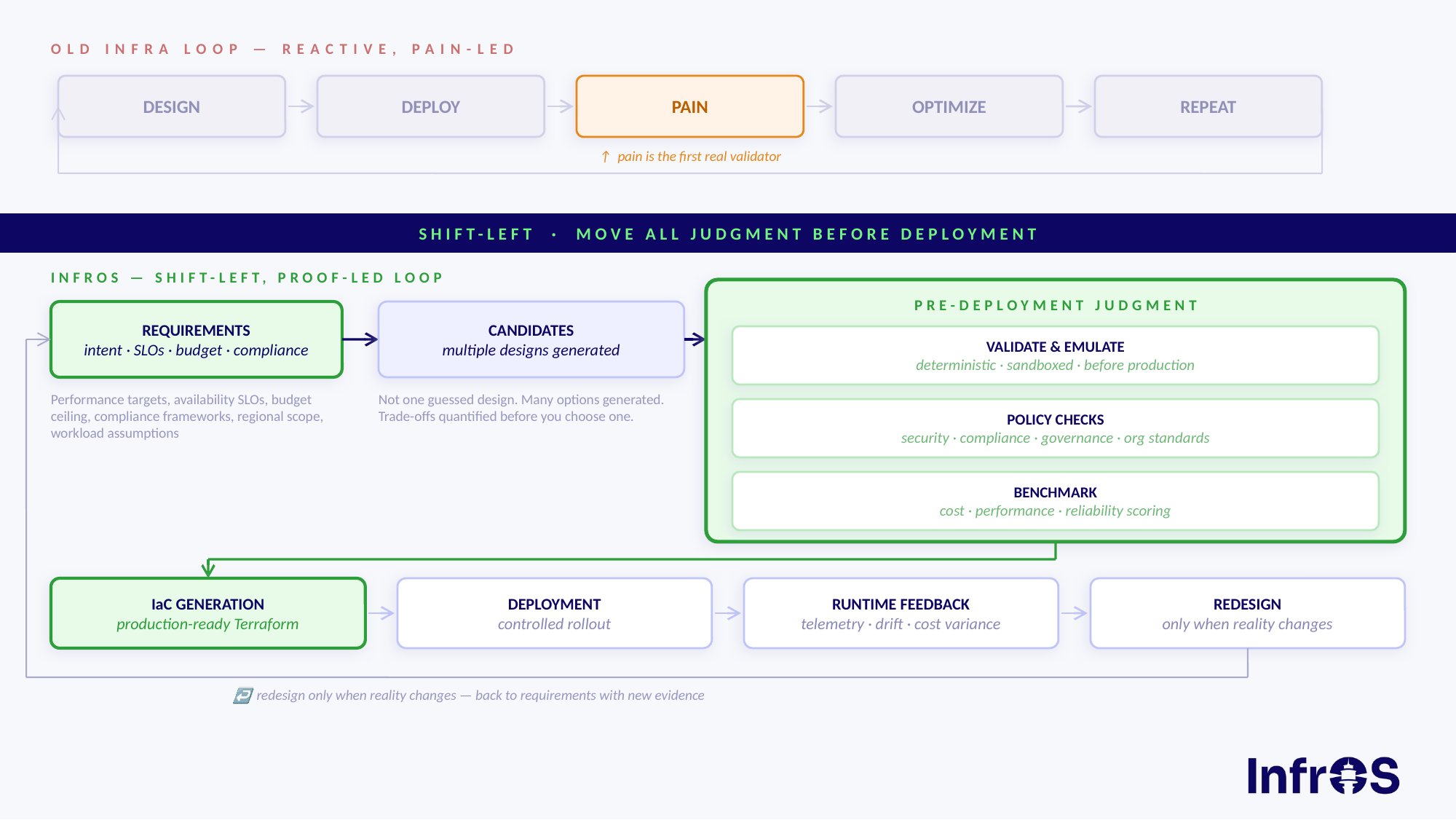
Most cloud teams follow the same painful loop: deploy, discover something's wrong, fix it in production, pay for the downtime and the rework, repeat. The problems aren't found at design time — they're found at 2am when something breaks, or at month-end when the bill arrives.
That's not an operations problem. That's a process problem.
The shift-left movement started in software development. The idea is that the earlier you catch a defect, the easier it is to fix. The same logic applies to cloud infrastructure. But almost no one is applying it there. Until now.
What Does "Shift Left" Mean in Cloud Infrastructure?
In traditional cloud workflows, design decisions get validated after deployment. You spin up resources, run them for a few weeks, and then react: the costs are higher than expected, the latency is worse than estimated, the architecture doesn't actually meet your compliance requirements.
Shift-left cloud infrastructure means moving all of that validation before deployment. Before a single resource is provisioned, you should already know:
What this architecture will cost, across regions and account configurations
- Whether it meets your performance, resilience and availability targets
- Where the compliance, security, and policy gaps are
- How it behaves under real load conditions
If you can answer those questions at design time, you deploy with confidence — not fingers crossed.
The Full Loop: From Requirements to Redesign
Most tools address one or two stages of the cloud lifecycle. InfrOS covers the entire loop — and critically, treats it as a loop, not a one-way pipeline.
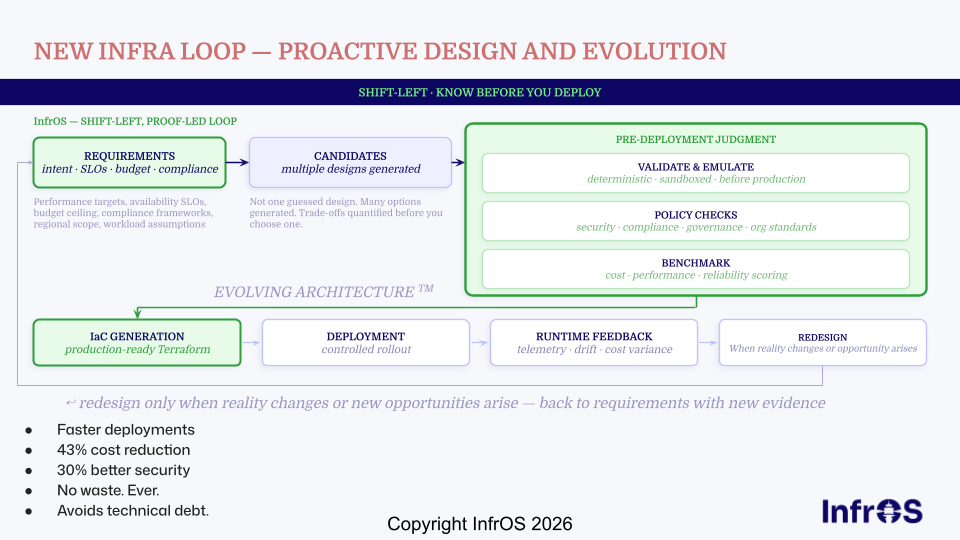
1. Requirements Gathering Start with what you actually need: performance targets, budget constraints, compliance standards, regional coverage, availability requirements. These aren't afterthoughts. They're inputs. Everything else flows from them.
2. Generate Architecture Candidates Based on those requirements, InfrOS generates multiple architecture candidates — not a single opinionated default. Different trade-offs, different configurations, structured options that reflect your actual parameters: which services, which regions, which account structure.
3. Deterministic Validation and Emulation in a Sandbox This is where most tools stop short. Before anything touches production, InfrOS validates and emulates the candidate architectures in a sandboxed environment. Behavior is tested deterministically — no guessing, no "we'll see when it's live."
4. Evaluation, Policy Checks, and Benchmarking With emulation results in hand, InfrOS runs full evaluation across multiple dimensions: cost, performance, reliability, resilience, security, maintainability, and deployment complexity. Policy checks surface compliance gaps before they become audit findings. Benchmarks give you real numbers, not estimates, against your requirements.
5. Production-Ready IaC Generation Once a validated architecture clears evaluations and benchmarking, InfrOS generates production-ready Infrastructure as Code. The IaC isn't a starting point for manual editing — it's the output of a design process that's already been proven.
6. Deployment With everything validated ahead of time, deployment is a confirmation, not an experiment. You're not hoping the architecture holds up — you already know it does.
7. Runtime Feedback → Redesign When Reality Changes Live environments drift. Requirements evolve. Business context shifts. InfrOS collects runtime feedback and uses it to inform the next design cycle — which starts back at step one, but this time with real data about how the world actually behaved. That's not patching. That's InfrOS’s Evolving ArchitectureTM
Why This Matters: The Cost of Getting It Wrong After Deployment
Cloud infrastructure mistakes are expensive in two ways: the direct cost of running a misconfigured architecture, and the engineering time to diagnose and fix it. And that is without accounting for the end-user experience that might be impacted
A few data points from InfrOS deployments:
- 43% average infrastructure cost reduction when architecture is validated at design time versus post-deployment
- 63% faster deployment cycles when teams go into provisioning with proven, pre-validated designs
- Fortune 500 organizations using InfrOS have eliminated entire rounds of post-deployment rework
These aren't numbers from theoretical benchmarks. They come from real architectures that went through the shift-left process instead of the traditional deploy-and-discover approach.
This Is Not a FinOps Tool
Worth being explicit about this, because the category gets conflated constantly.
FinOps is about managing cloud spend after the fact — tagging resources, chasing anomalies, building dashboards that show you what you already spent. It's useful. It's also fundamentally reactive.
InfrOS operates across a different set of dimensions — cost, performance, resilience, security, availability, and deployment complexity — and it operates at design time, not analysis time. The goal isn't to report on what went wrong. It's to engineer something that won't.
If you're already running FinOps tooling and happy with it, InfrOS doesn't replace it. It operates upstream, at the layer where the decisions are actually made.
The Proof Is Part of the Product
"Optimized Cloud Design & Deployment. Proof Included."
That tagline isn't marketing language. It's a description of how the platform works. When InfrOS generates an architecture, the emulation results, benchmark data, and policy check reports are part of the deliverable — not an appendix, not an optional report. You deploy knowing what you're deploying and why it's the right design for your requirements.
That's the shift-left promise: by the time you hit deploy, the hard work is already done.
Who Should Be Reading This
If you're building cloud infrastructure for a company that takes reliability seriously — whether that's an engineering team at a scaling startup, a platform team at an enterprise, or an MSP managing infrastructure for clients — the shift-left model is directly relevant to you.
The teams getting the most out of InfrOS tend to share a few characteristics:
- They've been burned by post-deployment surprises before
- They're working across multiple AWS accounts, regions, or compliance frameworks
- They're responsible for both moving fast and getting it right
If that sounds familiar, the methodology is worth understanding before your next deployment cycle.
Start With Design, Not Deployment
The shift-left revolution in cloud infrastructure isn't a trend. It's a straightforward realization: the later you find a problem, the more it costs to fix it.
InfrOS exists to move that discovery earlier — all the way to the design stage, before anything is running and before any resources are provisioned against the wrong architecture.
Ready to see what your next architecture looks like before you deploy it? Request a demo today.

8 Best Cloud Cost Optimization Tools for 2026
Key Takeaways
- Multi-cloud, Kubernetes, serverless, and ephemeral infra have made cloud costs harder to track and control, leading to structural inefficiencies.
- AI is accelerating cloud cost growth and waste, increasing compute and storage demands.
- Modern cost optimization tools automate optimization through rightsizing, cleanup, scheduling, policy enforcement.
- AI is becoming the control layer for FinOps with chatbots, auto-generated dashboards, anomaly detection, “next best action” recommendations, and autonomous agents.
- Quick wins come through idle cleanup and rightsizing, but real impact comes when optimization becomes continuous and embedded in workflows.
- InfrOS delivers waste-free infrastructure, reducing the need for cost optimization cleanup.
Why Cloud Cost Optimization has Become a Priority in 2026
Cloud environments have grown significantly more complex over the past few years. Teams are now managing multi-cloud deployments, Kubernetes clusters, serverless workloads, and ephemeral infrastructure.
This sprawl leads to new cost management and optimization challenges:
- New cost variables that are difficult to understand and track manually.
- Unused resources, overprovisioned instances, and inefficient scaling policies. 25% of cloud spend is estimated to be wasted.
- Limited visibility across transient environments makes it difficult to track spend accurately, allocate costs, and identify optimization opportunities.
In addition, the growing adoption of AI agents and systems is further increasing cloud spend. Cloud compute is required for model inference, large-scale data processing and storage, continuous experimentation, and serving AI-driven features in real time. The massive resources required can quickly inflate cloud bills.
What to Look for in Cloud Cost Optimization Software
Cloud cost optimization software helps teams monitor, analyze, and reduce cloud spending through automated insights and actions. The most effective platforms go beyond dashboards and provide direct operational impact.
Here’s what to look for:
Visibility & Reporting
- Multi-cloud support (AWS, Azure, GCP) with unified dashboard
- Real-time cost monitoring and granular spend breakdowns
- Tagging and cost allocation by team, project, or environment (unit economics)
- Historical trend analysis and forecasting
Optimization Recommendations
- Rightsizing suggestions for underutilized resources
- Idle resource detection and automated cleanup
- Reserved instance / savings plan recommendations
- Spot/preemptible instance guidance
- AI-driven recommendations (not just static rules)
Automation
- Automated scheduling (e.g., shutting down dev environments at night)
- Auto-scaling policies and enforcement
- Policy-based guardrails to prevent overspending
- One-click or fully automated remediation
Budgeting & Alerts
- Custom budget thresholds per team, service, or account
- Anomaly detection with real-time alerts
- Forecasting to project end-of-month spend
Governance & Accountability
- Role-based access control
- Showback/chargeback reporting for internal billing
- Audit logs and compliance tracking
Integrations
- Native cloud billing API integrations
- Ticketing tools (Jira, ServiceNow) for remediation workflows
- FinOps/ITSM tool compatibility
- Kubernetes and container cost visibility
Ease of Use
- Quick setup with minimal configuration
- Actionable insights (not just raw data)
- Clear ROI tracking - savings achieved vs. software cost
Support & Pricing
- Transparent vendor pricing (flat fee vs. % of spend)
- Strong onboarding and customer success support
- Regular updates as cloud pricing models evolve
Best Cloud Cost Optimization Tools List for 2026
With so many cloud cost optimization tools to choose from, it might be confusing to choose the right tool for your needs. To help, we compiled a list of the top tools. They were evaluated based on automation capabilities, AI-driven insights, Kubernetes support, multi-cloud coverage, and ease of integration into engineering workflows.
1. InfrOS
InfrOS is an IT infrastructure operating system that approaches cost optimization by preventing waste before it even occurs. It focuses on designing, emulating, and validating inherently optimized architectures and architectural decisions to eliminate technical debt from the get-go.
Top Features
- Emulation and benchmarking of cloud architectures in a simulation lab
- Generation of a validated, ready-to-deploy Terraform code (IaC)
- Continuous lifecycle optimization to prevent configuration drift
- Risk-free migration planning across multi-cloud or hybrid setups.
Recommended Use Cases
Use InfrOS when you are deploying new cloud architecture or migrating systems and want to ensure you "ship right the first time" with perfectly aligned, waste-free infrastructure, or when you need to optimize existing evolving architecture and changing cloud elements.
2. ScaleOps
ScaleOps is an autonomous, real-time resource optimization platform focused on Kubernetes and AI infrastructure. It dynamically rightsizes workloads in production environments for cutting cloud costs.
Top Features
- Automated real-time pod rightsizing for CPU and memory resource requests.
- Replica optimization that dynamically manages triggers and scales
- GPU workload rightsizing, offering automated optimization for real-time demand
- Spot, Node, and Karpenter optimization to efficiently utilize nodes and eliminate underutilized capacity.
Recommended Use Cases
Choose ScaleOps when you are looking for an autonomous solution for your K8s and AI infrastructure.
3. Cast AI
Cast AI is an application performance automation platform for Kubernetes and cloud applications. It proactively rightsizes workloads and manages infrastructure to improve performance and shrink costs.
Top Features
- Self-healing AI Agents that remediate drift and automatically fix operational issues without tickets.
- Precision workload rightsizing for CPU and memory requests.
- Infrastructure automation including GPU allocation, node scaling, and intelligent workload placement.
- Spot instance interruptions predictions
Recommended Use Cases
Choose Cast AI for use cases requiring autonomous solutions for K8s and app performance and when using Spot instances.
4. OpenOps
OpenOps is a no-code, open-source FinOps automation solution that helps organizations connect their existing visibility tools and multi-cloud environments so they can create optimization and remediation workflows.
Top Features
- No-code customizability with unlimited steps, conditional branching, and thresholds to build workflows from scratch.
- Pre-packaged workflows for top FinOps domains
- Multiple integrations with public clouds, FinOps tools, DevOps tools, and communication platforms.
- Human-in-the-loop approvals to streamline feedback loops and avoid blind automation.
Recommended Use Cases
Choose OpenOps if you are a FinOps practitioner who needs highly customizable workflows without wanting to write code, and you need to maintain tight governance.
5. PointFive
PointFive provides deep waste detection and agentic remediation for cloud and AI efficiency.
Top Features:
- DeepWaste Detection featuring over 400 optimization types across AWS, Azure, GCP, Kubernetes, Snowflake, Databricks, and more.
- Agentic Remediation, where AI coding agents generate contextual IaC fixes
- Optimization for AI, analyzing GPU instance rightsizing, model selection, prompt caching, and provisioned throughput.
- Workflow automation routing tasks via Jira, Slack, or ServiceNow to accelerate resolution.
Recommended Use Cases
Use PointFive when you need to uncover deep architectural waste (including complex AI infrastructure costs) and want to speed up implementation by providing your engineers with ready-to-deploy IaC fixes directly in their workflows.
6. IBM Turbonomic
IBM Turbonomic is an application resource management platform for hybrid and multicloud environments. It optimizes compute, storage, and network resources to real-time, for optimizing performance.
Top Features
- Full-stack visibility that continuously analyzes applications, VMs, containers, and infrastructure to map resource flows and dependencies.
- Policy-driven automation for executing safe, auditable actions
- Rightsizing compute, storage, network and GPU resources based on live demand.
- Data center, Kubernetes, and cloud optimization.
Recommended Use Cases
Choose IBM Turbonomic if you’re a large enterprise with a complex hybrid IT infrastructures(mixing on-premises data centers, VMs, and multicloud environments).
7. Harness
Harness provides an AI-powered FinOps tool that provides recommendations, reports and answers to natural language questions.
Top Features
- Reporting and visibility for cost allocation, kubernetes, chargeback/showback and anomaly detection.
- Automated surfacing of insights and optimization opportunities.
- Automated policy creation and remediation
- AutoStopping of idle resources
- Commitment Orchestrator for automated purchasing and management of Instances
- Cluster Orchestrator for autoscaling with spot orchestration and bin packing
Recommended Use Cases
Use Harness when you want to rely on AI for cost optimization management
8. Wiv
Wiv is an AI-powered FinOps workflow automation platform that provides cloud cost optimization recommendations and uses conversational AI to automate routines and enforce governance.
Top Features
- AI FinOps agent, which learns business context, alerts teams to cost spikes, and answers cost questions in natural language.
- Low-code or natural language options for building tailored optimization workflows.
- Advanced filtering options for case management
- Human-in-the-loop approvals
- Real-time dashboards
Recommended Use Cases
Choose Wiv if you’re looking for a no-code interface and an AI copilot for building and enforcing your workflows.
How AI Tools are Changing Cloud Cost Optimization
AI tools for cloud cost optimization use ML models, LLMs and MCP servers to automate and enhance and deliver cost optimization workflows. These systems continuously learn from workload behavior to predict usage, identify anomalies and adjust rightsizing recommendations over time. They can reduce cloud costs by 15-35% through real-time alerts and recommendations, with tools like InfrOS reducing costs by 43% as well as time to deployment.
With AI in cloud cost optimization, teams can:
- Automate rightsizing recommendations - Continuously analyze resource utilization and suggest or automatically apply optimal instance types and sizes, eliminating manual guesswork
- Predict and prevent cost spikes - Use forecasting models to anticipate usage surges before they occur, enabling proactive budget controls rather than reactive fixes
- Detect anomalous spending in real time - Identify unusual cost patterns the moment they emerge, reducing the window between a misconfiguration and its financial impact
- Optimize reserved instance and savings plan coverage - Analyze historical usage trends to recommend the right mix of commitment-based pricing, maximizing discounts without over-committing
- Eliminate idle and zombie resources - Surface underutilized VMs, orphaned snapshots, and forgotten storage buckets that accumulate costs silently over time
- Accelerate FinOps workflows - Reduce the manual effort of tagging audits, cost allocation, and reporting, freeing engineers to focus on higher-value work
- Improve multi-cloud visibility - Consolidate spending insights across AWS, Azure, and GCP into unified recommendations, making cross-cloud tradeoffs easier to evaluate
- Answer cost questions via chatbot - Allow teams to ask natural language questions like “Why did spend spike yesterday?” and get immediate, contextual answers
- Generate dashboards on demand - Turn prompts into real-time cost views, breaking down spend by service, team, or workload without manual setup.
- Recommend next best actions - Go beyond insights to suggest exactly what to do next, from shutting down resources to changing pricing models.
- Operationalize MCP integrations - Connect AI agents to cloud and FinOps systems through MCP to take action (e.g. resize instances, apply policies) directly from insights
- Unify context across tools - Pull data from billing, observability, and infra into a single ai-driven view, reducing fragmentation and decision latency
FAQs
How do cloud cost optimization tools differ from FinOps platforms?
Cloud cost optimization tools focus on identifying and reducing infrastructure waste through automation and technical insights. FinOps platforms guide decision-making and budgeting by connecting spend to business units, enforcing policies, forecasting usage, and enabling teams to track unit economics and ROI.
Are cloud cost optimization solutions safe for production workloads?
Most modern solutions are designed with safeguards such as approval workflows, policy controls, and rollback mechanisms to ensure safe operation in production. Teams can configure automation levels, starting with recommendations before enabling execution, minimizing the risk of performance impact or unintended disruptions.
Can cloud cost optimization software support Kubernetes environments?
Yes, many modern tools provide Kubernetes-native support, offering visibility into pod-level costs, idle resources, and cluster efficiency. They also deliver rightsizing recommendations and workload optimization strategies specifically tailored to containerized environments, which are now central to most cloud architectures.
How quickly can teams see ROI from cloud cost optimization services?
Teams often begin seeing measurable savings within weeks, especially when addressing obvious inefficiencies like idle resources or overprovisioned instances. Full ROI typically depends on adoption depth, but organizations that integrate optimization into engineering workflows can achieve continuous and compounding cost reductions.
Do AI-powered tools replace manual infrastructure optimization?
AI-powered tools significantly reduce the need for manual optimization by automating analysis and remediation, but they do not fully replace human oversight. Engineers are still responsible for defining policies, validating changes, and aligning optimization efforts with performance, reliability, and business requirements.
Cloud Infrastructure Optimization Best Practices for Modern DevOps Environments
Key Takeaways
- Cloud infrastructure optimization is now a continuous engineering discipline, not a one-time cleanup project, organizations that treat it as quarterly housekeeping routinely overpay.
- The most common sources of cloud waste are overprovisioned compute, idle resources, and misconfigured Kubernetes clusters - all of which are solvable with the right visibility and automation in place.
- Effective cloud infrastructure cost optimization strategies combine rightsizing, commitment management, autoscaling tuning, and storage lifecycle policies into a consistent, repeatable practice.
- DevOps teams can embed cost controls directly into CI/CD pipelines, shifting optimization left so it happens before waste reaches production.
- Platforms like InfrOS are designed to automate and enforce infrastructure optimization continuously, aligning your cloud spend with your actual business needs.
Why Cloud Infrastructure Optimization Is No Longer Optional
Cloud adoption moved fast. For most organizations, that speed came at a cost: environments built in a hurry, provisioned conservatively to avoid downtime, and never fully revisited. The result is a sprawling infrastructure that delivers less than it costs.
According to industry estimates, organizations waste between 30% and 35% of their cloud spend on idle or underutilized resources. That number climbs higher in multi-cloud and Kubernetes-heavy environments, where visibility breaks down across team boundaries.
The shift from on-prem to cloud was supposed to unlock efficiency. In many cases, it hasn't, because the tools and habits used to manage physical infrastructure don't map to the dynamic, metered reality of cloud. Cloud infrastructure cost optimization isn't a cost-cutting measure. It's a discipline that ensures your infrastructure actually serves your business rather than outpacing it.
For engineering managers and FinOps teams, this matters more than ever. Cloud budgets now sit alongside headcount as a major line item. Boards and CFOs want accountability. And the engineering teams building and running infrastructure are increasingly the ones being asked to explain the bill.
The most effective organizations are responding with a fundamentally different approach: shift-left optimization. Rather than deploying infrastructure and then reactively fixing the cost and performance issues that emerge, they design correctly from the start - simulating, benchmarking, and validating infrastructure before a single resource is provisioned. Optimization built into the design phase is cheaper, faster, and more reliable than optimization performed after the fact.
Core Drivers of Cloud Infrastructure Cost Inefficiency
Before you can fix a problem, you need to understand where it lives. Most cloud cost inefficiency traces back to a handful of predictable patterns.
Overprovisioned Compute
When teams size infrastructure for peak load or worst-case scenarios, they lock in resources that sit idle most of the time. A VM provisioned for a batch job that runs three hours a day is burning money for the other twenty-one. This is one of the most common, and most fixable, sources of waste.
Idle and Orphaned Resources
Cloud environments accumulate technical debt quickly. Snapshots, load balancers, reserved IPs, and storage volumes tied to workloads that no longer exist quietly generate charges with no one noticing. Without a systematic review process, these orphaned resources compound over time.
Inefficient Autoscaling Configurations
Autoscaling is one of the most valuable features in cloud infrastructure, and one of the most misused. Scaling thresholds set too conservatively prevent cost savings from ever materializing. Scaling triggers that react too slowly leave your application struggling under load while the bill climbs. Getting autoscaling right requires tuning based on real traffic patterns, not defaults.
Misconfigured Kubernetes Clusters
Kubernetes adds power and flexibility to infrastructure, but also a new layer of complexity that directly affects cost. CPU and memory requests set without analysis lead to wasted node capacity. Namespace-level cost visibility is often absent. Persistent volumes outlive their workloads. Many organizations running Kubernetes have limited visibility into what their clusters actually cost at the service or team level.
Unmanaged Commitment Strategies
Cloud providers offer significant discounts for committed usage, Reserved Instances on AWS, Committed Use Discounts on GCP, Reserved Capacity on Azure. Teams that haven't developed a disciplined approach to commitment purchasing consistently pay on-demand rates for workloads that have been running steadily for months or years.
Proven Cloud Infrastructure Cost Optimization Strategies
The most resilient approach to cloud infrastructure cost optimization is designing infrastructure correctly before it ships, not patching it afterward. Shift-left optimization means treating cost, performance, and reliability as design constraints, not post-deployment concerns. The strategies below operate at two levels: getting new infrastructure right from the start, and continuously improving what's already running.
Rightsizing Compute Resources
Rightsizing means matching instance types and sizes to actual utilization, not projected maximums. Start by pulling two to four weeks of CPU and memory utilization data across your compute inventory. Identify instances running consistently below 40% utilization. Downsize them, test for performance impact, and iterate. Done systematically, rightsizing alone can reduce compute costs by 20–30% without any change to architecture.
Autoscaling Tuning
Revisit every autoscaling policy with actual traffic data in hand. Set scale-out thresholds based on observed peak demand rather than worst-case assumptions. Build in scale-in aggressiveness, many defaults are too conservative and leave over-provisioned capacity running during low-traffic windows. For Kubernetes, review Horizontal Pod Autoscaler settings per workload and ensure Vertical Pod Autoscaler recommendations are factored into resource requests.
Commitment Management
Develop a rolling commitment strategy: analyze which workloads have run steadily for 90 days or more and convert those to reserved or committed pricing. Review commitments quarterly. Use Savings Plans on AWS for flexibility across instance families, and layer spot or preemptible instances for non-critical, fault-tolerant workloads like batch processing, CI/CD jobs, and data pipelines.
Storage Lifecycle Policies
Most organizations have no enforced policy for what happens to data after it's no longer actively used. Implement tiering: move infrequently accessed data to lower-cost storage classes automatically. Set expiry policies on snapshots. Archive or delete log data beyond a defined retention window. Storage optimization tends to have a quieter ROI than compute, but it accumulates meaningfully at scale.
Workload Scheduling
Not all workloads need to run around the clock. Development and staging environments, scheduled jobs, and batch workloads that run overnight can be stopped during off-hours and weekends. Even simple scheduling automation can cut non-production environment costs by 60–70%.
Cost Optimization Tips for Cloud Infrastructure in DevOps Environments
Optimization works best when it's embedded into the way teams work every day, ideally before infrastructure is deployed at all. The shift-left model means catching cost and performance issues at the design and code review stage, not after they've been running in production for weeks. Here are practical ways engineering teams can make that real.
- Validate and benchmark infrastructure before deploying it. The most effective way to avoid production optimization problems is to not introduce them in the first place. Tools like InfrOS emulate the target environment to verify that generated IaC is actually deployable and benchmark it against performance and cost targets before a single resource is provisioned. This eliminates an entire class of reactive fixes.
- Define resource request standards for Kubernetes. Establish organization-wide defaults for CPU and memory requests and limits. Enforce them through admission policies so under-specified workloads don't make it to production.
- Include cost impact in infrastructure pull requests. Tooling exists to estimate the cost delta of infrastructure changes before they're merged. Building this into CI/CD gives engineers real-time feedback and creates a culture of cost awareness without requiring a separate review process.
- Tag everything from day one. Cost allocation only works if your resources are consistently tagged by environment, team, service, and cost center. Make tagging a deployment requirement, not an afterthought. Untagged resources should fail validation in your IaC pipeline.
- Set up anomaly detection alerts. All major cloud providers offer cost anomaly detection. Enable it, tune the sensitivity, and route alerts to the engineering team that owns the affected resources, not just the FinOps or finance team.
- Review cloud costs in engineering standups. Cost should be a first-class metric alongside latency, error rate, and deployment frequency. A weekly cost review, even a brief one, builds accountability and surfaces waste before it compounds.
- Automate idle resource cleanup. Use policies or tooling to detect and flag, or automatically terminate, resources that have been idle for more than a defined threshold. This applies to stopped instances, unused load balancers, unattached volumes, and stale snapshots.
FAQ
How often should cloud infrastructure cost optimization be performed?
More often than most teams realize. Even if your workloads don't change, your cloud environment does, providers continuously update pricing, introduce new instance types, retire older ones, and launch services that can replace more expensive configurations. What was the optimal setup six months ago may no longer be. Beyond reactive reviews, teams should treat optimization as a continuous background process: weekly cost review cadences, automated anomaly alerts, and tooling that monitors infrastructure drift in near real-time rather than waiting for a quarterly audit to surface waste.
Is infrastructure-level optimization safe for production workloads?
Yes, and the safest way to get there is to validate infrastructure before it reaches production in the first place. Platforms like InfrOS emulate the target environment and benchmark generated IaC against performance and cost targets prior to deployment, so issues are caught at the design stage rather than after they're live. For optimizing existing production workloads, the approach is incremental: test in lower environments first, monitor performance closely after each change, and adjust gradually rather than making sweeping modifications at once.
How does Kubernetes affect cloud infrastructure optimization?
Kubernetes introduces a layer of cost complexity that sits between your applications and the underlying cloud infrastructure. Poorly configured resource requests and limits lead to over-provisioned or under-utilized nodes. Namespace-level cost attribution is often missing by default. Effective cloud infrastructure optimization in Kubernetes environments requires dedicated visibility tools and consistent resource governance policies across clusters.
What metrics matter most for cloud infrastructure cost optimization?
The most actionable metrics are CPU and memory utilization per instance or pod, cost per unit of business output (unit economics), idle resource percentage, commitment coverage ratio, and storage utilization by tier. Tracking these consistently allows teams to prioritize optimization efforts by impact rather than guessing where waste lives.
Can optimization reduce performance risks while lowering costs?
Yes, and this is one of the most misunderstood aspects of infrastructure optimization. Oversized, misconfigured environments often perform worse than well-tuned ones. Fixing autoscaling policies improves responsiveness. Eliminating idle resources reduces noise in monitoring. Proper Kubernetes configuration improves scheduling efficiency. Done right, optimization improves reliability and performance while reducing spend.

GCP Migration Strategy: Tools, Risks, and Cost Considerations
Key Takeaways
- Strategy before servers: A GCP migration strategy starts with workload assessment, dependency mapping, and a separate data migration plan before anything moves.
- Costs go beyond compute: Factor in redesign labor, dual-environment overlap, and egress fees. Build optimization into the plan from day one, not after go-live.
- Business decision first: AI capabilities, cost flexibility, and operational resilience are the real drivers, not just a technical checkbox.
The difference between a smooth cloud migration and a painful one almost always comes down to what happens before anything moves.
Most organizations know they need to get to the cloud. But McKinsey research found that up to 75% of cloud migrations go over budget. The reasons tend to repeat: unclear dependencies, surprise costs, and workloads moved without a plan for how they'd run on the other side. Teams treat migration as a logistics problem when it's really an architecture problem.
A strong Google Cloud Platform (GCP) cloud migration strategy changes this by starting with workload assessment, dependency mapping, and cost modeling before a single server gets touched. When the foundation is right, the execution becomes predictable.
Explore how to plan and execute a Google Cloud Platform migration, what each phase requires, how data is handled, and what shapes the overall cost.
Why Organizations Are Prioritizing Google Cloud Platform Migration
Moving to GCP gives teams access to capabilities that are hard to build and sustain in-house.
AI and data capabilities
Google Cloud's AI and machine learning ecosystem, including BigQuery, Vertex AI, and TPUs, gives organizations a ready-made platform for analytics and ML workloads. For teams training models or deploying generative AI, GCP's infrastructure is already optimized for it.
Cost flexibility
GCP's pay-as-you-go model shifts IT spending from large upfront purchases to operational costs that scale with usage. Sustained-use discounts and committed-use programs add budget predictability on top of that.
Operational resilience and compliance
GCP runs on a globally distributed network with multi-region redundancy and self-healing infrastructure, delivering near-100% uptime for mission-critical services. On the compliance side, default encryption, Zero Trust architecture, and GDPR/HIPAA-aligned certifications make it a fit for regulated industries.
What Defines a Strong GCP Cloud Migration Strategy
A solid GCP migration plan starts with understanding your current environment, defining how each workload should move, and planning for potential risks.
The 6 Rs framework
Not every workload gets the same treatment. The 6 Rs give you a way to categorize each one based on its technical profile and business value.
- Rehost (lift and shift): Move as-is to Compute Engine VMs. Fastest path, fewest cloud-native benefits.
- Replatform (lift and optimize): Move with minor adjustments like shifting a database to Cloud SQL or containerizing for GKE.
- Refactor (re-architect): Rewrite for cloud-native patterns. Highest long-term ROI, biggest upfront effort.
- Repurchase: Replace legacy apps with cloud-based SaaS alternatives.
- Retire: Decommission apps that no longer serve a purpose.
- Retain: Keep certain workloads on-prem due to regulatory, latency, or complexity constraints.
The value of this framework is that it forces a decision for each workload rather than applying a blanket approach.
Related Content: The Top Cloud Cost Cutting Platforms
Workload assessment and dependency mapping
You can't migrate what you don't fully understand.
Automated discovery tools help catalog servers, databases, and infrastructure components, then map their dependencies. That dependency graph is what lets you group workloads into migration waves so interconnected systems move together instead of breaking apart mid-transfer.
Risk planning
Configuration drift, network bottlenecks, and data corruption are the kinds of problems that surface during execution if they aren't identified during planning.
Strong strategies address failure modes upfront. That means building rollback procedures, testing in isolated environments, and assigning priority levels to risks based on severity and likelihood. The goal is to make the final cutover a non-event.
Core Phases of a Google Cloud Migration
A Google Cloud Platform migration follows five phases. Each one builds on the last, and skipping ahead is where most projects start to break down.
Phase 1: Assessment
Start by taking inventory of what you have.
Automated discovery tools like the Google Cloud Migration Center catalog your on-prem assets, including servers, databases, and storage.
From there, benchmark current performance (latency, throughput, error rates) so you have a baseline to measure against. This is also where you build your total cost of ownership (TCO) comparison between your current setup and projected GCP spend.
Important questions to ask:
- What servers, databases, and storage systems are currently in production?
- What does our current environment cost to operate annually?
- Which workloads are candidates for migration and which need to stay on-prem?
Phase 2: Planning and foundation
This phase is about building what Google calls the "Landing Zone," your secure, scalable foundation in GCP. That includes setting up a resource hierarchy (Organization, Folders, Projects), defining IAM roles based on least-privilege access, designing VPC networking, and establishing connectivity to your existing environment through VPN or Cloud Interconnect.
Important questions to ask:
- How should our resource hierarchy be structured for billing and policy control?
- Who needs access to what, and at what permission level?
- How will we maintain connectivity between on-prem and cloud during the transition?
Phase 3: Execution
Move in waves, starting with non-critical applications or pilot workloads to validate the strategy. Use continuous background replication to keep the target environment in sync with the source. Orchestration tools handle launch sequencing, so applications come online in the right order.
Phase 4: Validation
Before the final cutover, test everything in isolated environments. Clone workloads into separate VPCs for functional and performance testing. Verify data integrity through row counts, checksums, and schema checks. Confirm that the target environment meets or exceeds the baseline you set during assessment.
Phase 5: Post-migration optimization
Once workloads are live, the work isn't done.
Rightsize instances based on actual usage data, transition rehosted VMs toward managed services like Cloud Spanner or GKE, and set up continuous governance using tools like Active Assist for ongoing recommendations on cost, security, and performance.
The common mistake is treating Phase 5 as optional. Optimization should be built into the plan from the start, not added on after go-live.
Designing a Successful Cloud Data Migration Strategy
Data migration is not the same as application migration. It needs its own plan, tools, and validation process. A cloud data migration strategy should cover where your data is going, how it gets there without downtime, and how you prove it arrived intact.
Database migration paths
Google Cloud offers managed options depending on your workload type, including:
Choosing the right target service early prevents rework later. Match each database to the service that fits its access patterns and scale requirements.
Minimizing downtime
The Database Migration Service (DMS) uses Change Data Capture (CDC) to replicate data in real time.
Your source database stays fully operational throughout the process. Every insert, update, and deletion gets captured and synced to GCP in the background.
When you're ready, the cutover is a simple repoint of the application to the new cloud endpoint. Schedule the final switch during off-peak hours with a documented rollback plan ready.
Data integrity validation
Google's open-source Data Validation Tool (DVT) automates the comparison between source and target databases. It runs checks at three levels: table level (row counts and filters), column level (schema and data type verification), and row level (hash comparisons for bit-level accuracy).
Catching a data discrepancy after cutover is significantly more expensive than catching it before.
Storage transfer
For non-database data like file systems and object storage, the Storage Transfer Service handles most scenarios.
For massive datasets where bandwidth is a constraint, Google's Transfer Appliance ships to your data center, gets loaded with up to several hundred terabytes, and returns to Google for upload.
Cost Considerations in a GCP Migration Plan
Migration costs don't stop at your monthly cloud bill. A realistic GCP migration plan should account for the full picture: what it takes to get there, what it costs to run, and where the savings actually come from.
Direct migration costs
Infrastructure redesign is often the biggest upfront expense. Dependency mapping, Landing Zone design, and re-architecture work all require skilled labor, and the scope scales directly with the complexity of your environment.
There's also the overlap period. Running dual environments during migration and validation is unavoidable, and it temporarily increases IT spending until the source environment is decommissioned.
Egress fees
Moving data out of an existing cloud provider used to be one of the most painful cost surprises.
Since 2024, Google, AWS, and Microsoft have started waiving egress fees for customers exiting their platforms permanently. The catch: it requires approval and a defined migration window, usually around 60 days.
Google Cloud incentives
Google offers several programs to lower the barrier to entry. The Rapid Migration and Modernization Program (RaMP) provides service credits based on incremental usage, plus funding for specialized partners to help with assessment and roadmap development.
For startups, the Google Cloud for Startups program offers up to $350,000 in credits over two years for companies building AI-focused products.
Long-term optimization
This is where the real savings show up. GCP's pricing model includes several built-in mechanisms for reducing spend over time.
- Sustained-use discounts: Automatic reductions for workloads that run consistently through a billing cycle.
- Committed-use discounts (CUDs): Significant reductions for one or three-year commitments.
- Spot VMs: Steep savings for fault-tolerant batch processing.
- Cold storage tiers: Archive or Coldline pricing for data that's rarely accessed.
Start Your GCP Migration With a Clear Plan
The difference between a migration that delivers value and one that drains budget comes down to preparation.
Most teams know what they want from GCP: better AI capabilities, cost flexibility, and infrastructure that scales without constant manual work. The challenge is getting there without the delays, overruns, and surprises that slow down the majority of migration projects.
InfrOS simplifies GCP migrations using an intelligent cloud infrastructure optimization engine that designs, simulates, and deploys cloud architecture across AWS, Azure, and GCP. It analyzes over 1,000 infrastructure parameters to generate optimized, deployment-ready configurations, cutting months of planning down to days.
Get a migration plan built on optimized, deployment-ready architecture. Book a demo to see how InfrOS gets you there.
FAQs
How long does a typical Google Cloud Platform migration take?
It depends on scope. Small projects with a few apps can wrap up in 2 to 6 weeks. Medium-scale moves typically take 2 to 4 months. Large enterprises with 50+ applications and complex legacy systems often need 6 to 18 months.
What workloads are most complex to migrate to GCP?
Legacy monoliths like large ERP systems and heavily customized Oracle databases. Anything built on proprietary hardware, custom middleware, or with circular dependencies between services will need significant refactoring or a phased wave approach.
How can teams reduce downtime during cloud data migration?
Use continuous replication through the Database Migration Service with Change Data Capture so the source stays live. Test in isolated VPCs before cutover. Schedule the switch during off-peak hours with a documented rollback plan ready.
Are Google Cloud migration tools sufficient for enterprise environments?
Google's native tools (Migration Center, Database Migration Service, Migrate to Virtual Machines) cover most use cases. For multi-cloud or non-standard setups, teams often supplement with third-party options for added flexibility.
When should optimization planning begin in a GCP migration plan?
During assessment, not after go-live. Set performance benchmarks and rightsizing targets before the move. Build cost controls like budget alerts and resource tagging into the Landing Zone from day one.

Top Cloud Cost Management Platforms For 2026

TL;DR: Key Takeaways
- Top Pick for 2026:
InfrOS. Built to handle the "Cloud Complexity" with automated workflows that actually respect engineering time. - The Shift:
Cloud spend is no longer a finance problem. It's a core engineering metric, just like latency or uptime. - Real-Time or Bust:
Quarterly reviews are dead. If you aren't optimizing continuously and automatically, you're overpaying. - Unit Economics:
Knowing your total bill isn't enough. You need to know exactly what it costs you to support a single customer or ship a specific feature.
When you’re scaling fast, finding the right cloud spend management platform isn’t about looking for more charts to ignore.
It’s about designing the right architecture before you deploy - so you don’t burn cash in the first place.
Why Cloud Cost Management Matters More Than Ever in 2026
In today's landscape, if you wait three months to catch a misconfigured dev environment, you've already nuked your margins. Modern teams have shifted to continuous cost optimization because the speed of the cloud demands it.
Costs now fluctuate by the minute, not the month. To keep your edge, you have to integrate cost data directly into your CI/CD pipelines. This ensures every deployment is evaluated for its fiscal impact before it ever touches production. It’s the only way to avoid those painful end-of-month conversations with finance.
Why Cloud Cost Management?
For a long time, the cloud bill was a CFO problem. They'd see a big number from AWS and ask you to "turn things off." We both know that doesn't work. Since you're the one provisioning resources, you're the only one who can actually control the spend.
This is driving the massive move toward engineering-driven accountability. You need a cloud cost management platform that shows you how your specific code changes impact the bottom line in real time. When you have that visibility, you can optimize on the fly, reducing friction and making "cost" just another part of the performance profile.
2026 Top Cloud Cost Management Platforms - 2026
Tools that handle multi-cloud complexity and deep container insights without adding more manual work to your plate dominate today’s leaders. Here is how the market looks right now.
1. InfrOS
InfrOS is designed for teams that want to fix cost at the infrastructure level - not apply patches to broken architectures.
- Shift-left architecture design based on actual product and business requirements.
- Capacity planning and holistic right-sizing aligned with performance and reliability goals - without permanent over-provisioning.
- Full cloud emulation to benchmark cost, performance, resilience, and security before deployment
- Vendor-agnostic, fully documented IaC with embedded policy and budget guardrails.
- CI/CD integration for continuous architectural optimization across new and existing environments.
2. Apptio Cloudability
Apptio is the go-to if your primary goal is giving finance full visibility and accountability over cloud spend across business units.
- Showback and chargeback across teams and cost centers
- Budgeting and forecasting based on historical spend
- ERP and finance system integrations
3. CloudHealth
If you're in a massive enterprise with heavy compliance needs, CloudHealth is a solid, established choice.
- Robust policy-driven governance and compliance controls.
- Deep integration if you're already in the VMware ecosystem.
- Extensive multi-cloud reporting for complex portfolios.
4. Finout
If you want flexible cost allocation without rebuilding your tagging strategy, Finout gives you layered visibility across cloud and SaaS spend.
- Virtual tagging layered on top of existing billing data.
- Custom cost grouping across cloud and SaaS.
- Supports strategic planning conversations.
5. CloudZero
If you want cloud cost treated as a product metric - not just a finance number - CloudZero is built around unit economics.
- Unit economics tracking aligned to products and customers.
- Cost allocation without heavy reliance on rigid tagging structures.
- Designed to connect engineering decisions with business outcomes.
6. Umbrella
If you’re looking for an AI-driven platform that helps you detect waste and plan future cloud spend across multi-cloud, Kubernetes, and SaaS - Umbrella is built for that.
- AI-driven detection of cost anomalies and waste
- Insights into spend trends to support planning decisions
- Designed to help teams prioritize cost issues to address
7. Kubecost
If your world is 100% Kubernetes, Kubecost provides the granular data you need to understand cluster costs.
- Detailed cost breakdown by cluster, namespace, deployment, and service.
- Open-source core for those who want to kick the tires first.
- Precise breakdown of storage, network, and compute within the cluster.
- Good for high-security, air-gapped environments.
8. Attribute
If tagging isn’t telling you the full story of who owns your cloud bill, Attribute is built to go deeper.
- Advanced cost attribution that maps spend to products, features, and services beyond basic tagging.
- Connects infrastructure usage patterns to real ownership.
- Designed to surface true cost drivers, not just billing categories.
9. PointFive
If your biggest frustration is discovering cloud waste long after the money is gone, PointFive is built to surface it early and clearly.
- Identifies idle, underutilized, and orphaned resources across cloud environments.
- Highlights actionable savings opportunities without requiring deep manual analysis.
- Designed to uncover cost inefficiencies that traditional dashboards often miss.
10. Infracost
Infracost is built for teams that want cost visibility directly inside their Infrastructure-as-Code workflows.
- Cost estimates embedded in Terraform pull requests.
- CI/CD integration for pre-deployment cost visibility.
- Developer-focused cost breakdowns.
- Helps teams compare infrastructure changes before merging.
Core Capabilities to Look for in Cloud Cost Management Tools
When you're choosing a cloud cost management platform, don't just look at the dashboard. Look for the features that actually support a FinOps cloud cost management strategy.
- Cost Modeling Beyond Spend: Reporting past spend isn’t enough. The right platform should simulate cost in different scenarios and structural waste before and after deployment.
- Kubernetes Visibility: If the tool can't see into your clusters at the label level, it's not going to help you.
- Unit Economics: You need to know your "cost per customer" or "cost per transaction" to see if your growth is actually healthy.
- Automated Optimization: A tool that just tells you there's a problem is just another alert. You want a tool that can actually model and fix it.
- Forecasting: Look for cloud cost management tools that use machine learning to give you a realistic look at where you'll be in six months.
FAQ
What’s the difference between cost visibility and cost optimization?
Visibility is just seeing the damage on a dashboard. It’s useful, but it doesn’t save you money. Optimization is the active, often automated, process of rightsizing resources and deleting waste. You need visibility to know where to look, but you need optimization to actually move the needle.
How long does it take to see ROI from Cloud Cost Management Platforms?
You should see a return within the first month or two. Usually, the "quick wins" come from killing orphaned resources or dev environments that should've been turned off weeks ago. The
long-term value comes from changing how your team actually models, builds, and deploys.
Are Cloud Cost Management platforms suitable for mid-sized engineering teams?
They're arguably more important for you. You don't have the infinite budget of a FAANG company, so every dollar wasted is a dollar you aren't spending on new features or dev. These platforms let you scale efficiently without needing a dedicated 10-person FinOps team.
Can these platforms manage AWS, Azure, and GCP together?
Most of the top-tier platforms are built for a multi-cloud world. They'll give you a unified view so you can compare costs across providers and avoid getting locked into one vendor's ecosystem. This is pretty much a standard requirement in 2026.
Why the Differences Matter
- Automation vs. Recommendation: Most enterprise tools like CloudHealth or Apptio are great at generating 50-page PDFs telling you that you're overspending. The problem is, they leave the actual work of fixing it to your already-slamped engineering team. We've built InfrOS to handle the remediation itself, so you aren't just seeing the problem, you’re solving it.
- Kubernetes Intelligence: Kubecost is fantastic if you live 100% inside a cluster, but it loses the plot the second you have to manage RDS, S3, or cross-cloud egress. We've combined that deep container granularly with a "whole-cloud" view.
- Shift-Left FinOps: We believe cost should be caught in the PR, not the bill. By integrating with your CI/CD pipelines, InfrOS makes it possible to see exactly how much a new feature will cost before it’s even merged.
Next Steps
Reduce structural cloud waste by up to 43% before traditional FinOps initiatives even begin - by engineering cost efficiency into your infrastructure and modeling spend before it hits your bill.

Leveraging Advanced Technology for Smarter Business Solutions at InfrOS
Intelligence Built Into Every Layer
The smartest businesses in the world share a common trait: they’ve embedded intelligence into their cloud operations at every level. From automated capacity planning to AI-powered incident response, InfrOS delivers the technology layer that makes this possible — without requiring a massive engineering team to maintain it.
From Reactive to Proactive Operations
Traditional IT operations are inherently reactive — teams respond to incidents after they happen, scramble to provision capacity during traffic spikes, and manually review logs to debug issues. InfrOS flips this model on its head by building proactive intelligence directly into the platform.
Advanced Capabilities Powering Smarter Operations
- Predictive Autoscaling: Anticipate demand spikes and pre-scale infrastructure before users are impacted.
- AI-Driven Root Cause Analysis: Automatically correlate signals across your stack to identify the root cause of incidents in minutes, not hours.
- Automated Compliance Checks: Continuously validate your infrastructure against security and compliance policies.
- Smart Cost Recommendations: Receive actionable suggestions to rightsize resources and eliminate waste.
Empowering Teams to Move Faster
When your infrastructure is smart, your teams don’t need to babysit it. InfrOS handles the operational toil so that engineers can focus on high-value work: building features, improving reliability, and innovating for customers.
The Business Case for Smarter Infrastructure
Organizations that invest in intelligent infrastructure see returns not just in cost savings, but in speed, reliability, and developer happiness. In a talent market where retaining great engineers is harder than ever, giving them the tools to do their best work is a competitive advantage in itself.