Key Takeaways
- Cloud infrastructure optimization is now a continuous engineering discipline, not a one-time cleanup project, organizations that treat it as quarterly housekeeping routinely overpay.
- The most common sources of cloud waste are overprovisioned compute, idle resources, and misconfigured Kubernetes clusters - all of which are solvable with the right visibility and automation in place.
- Effective cloud infrastructure cost optimization strategies combine rightsizing, commitment management, autoscaling tuning, and storage lifecycle policies into a consistent, repeatable practice.
- DevOps teams can embed cost controls directly into CI/CD pipelines, shifting optimization left so it happens before waste reaches production.
- Platforms like InfrOS are designed to automate and enforce infrastructure optimization continuously, aligning your cloud spend with your actual business needs.
Why Cloud Infrastructure Optimization Is No Longer Optional
Cloud adoption moved fast. For most organizations, that speed came at a cost: environments built in a hurry, provisioned conservatively to avoid downtime, and never fully revisited. The result is a sprawling infrastructure that delivers less than it costs.
According to industry estimates, organizations waste between 30% and 35% of their cloud spend on idle or underutilized resources. That number climbs higher in multi-cloud and Kubernetes-heavy environments, where visibility breaks down across team boundaries.
The shift from on-prem to cloud was supposed to unlock efficiency. In many cases, it hasn't, because the tools and habits used to manage physical infrastructure don't map to the dynamic, metered reality of cloud. Cloud infrastructure cost optimization isn't a cost-cutting measure. It's a discipline that ensures your infrastructure actually serves your business rather than outpacing it.
For engineering managers and FinOps teams, this matters more than ever. Cloud budgets now sit alongside headcount as a major line item. Boards and CFOs want accountability. And the engineering teams building and running infrastructure are increasingly the ones being asked to explain the bill.
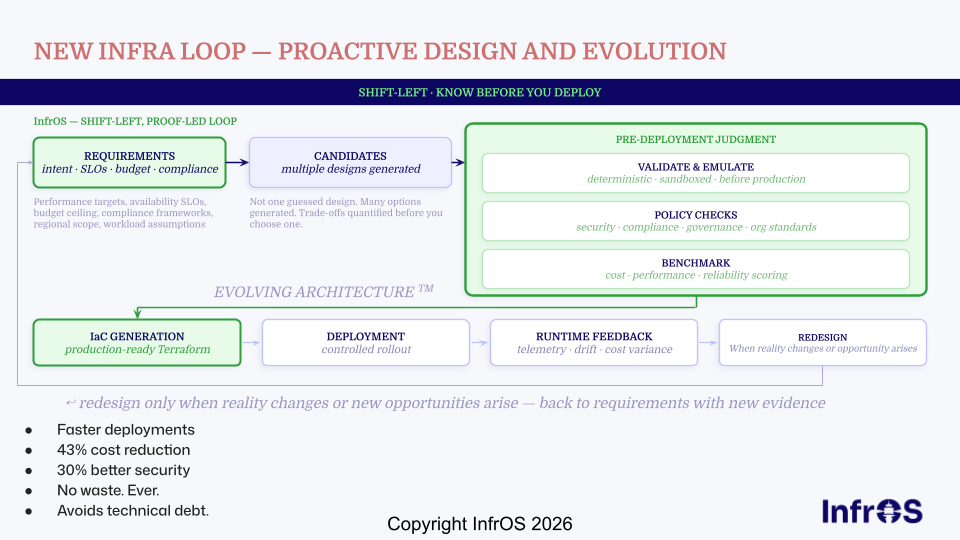
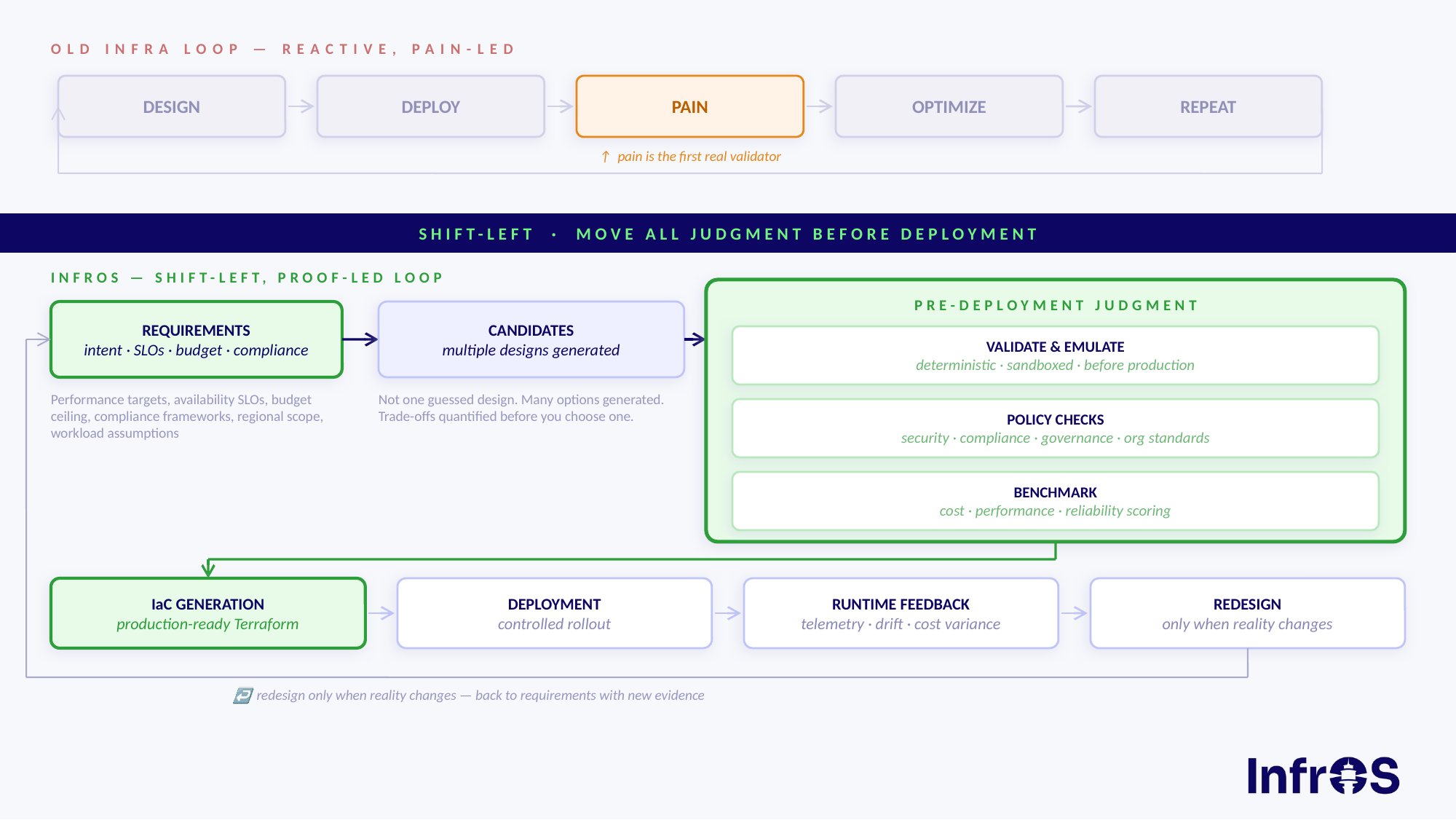
The most effective organizations are responding with a fundamentally different approach: shift-left optimization. Rather than deploying infrastructure and then reactively fixing the cost and performance issues that emerge, they design correctly from the start - simulating, benchmarking, and validating infrastructure before a single resource is provisioned. Optimization built into the design phase is cheaper, faster, and more reliable than optimization performed after the fact.
Core Drivers of Cloud Infrastructure Cost Inefficiency
Before you can fix a problem, you need to understand where it lives. Most cloud cost inefficiency traces back to a handful of predictable patterns.
Overprovisioned Compute
When teams size infrastructure for peak load or worst-case scenarios, they lock in resources that sit idle most of the time. A VM provisioned for a batch job that runs three hours a day is burning money for the other twenty-one. This is one of the most common, and most fixable, sources of waste.
Idle and Orphaned Resources
Cloud environments accumulate technical debt quickly. Snapshots, load balancers, reserved IPs, and storage volumes tied to workloads that no longer exist quietly generate charges with no one noticing. Without a systematic review process, these orphaned resources compound over time.
Inefficient Autoscaling Configurations
Autoscaling is one of the most valuable features in cloud infrastructure, and one of the most misused. Scaling thresholds set too conservatively prevent cost savings from ever materializing. Scaling triggers that react too slowly leave your application struggling under load while the bill climbs. Getting autoscaling right requires tuning based on real traffic patterns, not defaults.
Misconfigured Kubernetes Clusters
Kubernetes adds power and flexibility to infrastructure, but also a new layer of complexity that directly affects cost. CPU and memory requests set without analysis lead to wasted node capacity. Namespace-level cost visibility is often absent. Persistent volumes outlive their workloads. Many organizations running Kubernetes have limited visibility into what their clusters actually cost at the service or team level.
Unmanaged Commitment Strategies
Cloud providers offer significant discounts for committed usage, Reserved Instances on AWS, Committed Use Discounts on GCP, Reserved Capacity on Azure. Teams that haven't developed a disciplined approach to commitment purchasing consistently pay on-demand rates for workloads that have been running steadily for months or years.
Proven Cloud Infrastructure Cost Optimization Strategies
The most resilient approach to cloud infrastructure cost optimization is designing infrastructure correctly before it ships, not patching it afterward. Shift-left optimization means treating cost, performance, and reliability as design constraints, not post-deployment concerns. The strategies below operate at two levels: getting new infrastructure right from the start, and continuously improving what's already running.
Rightsizing Compute Resources
Rightsizing means matching instance types and sizes to actual utilization, not projected maximums. Start by pulling two to four weeks of CPU and memory utilization data across your compute inventory. Identify instances running consistently below 40% utilization. Downsize them, test for performance impact, and iterate. Done systematically, rightsizing alone can reduce compute costs by 20–30% without any change to architecture.
Autoscaling Tuning
Revisit every autoscaling policy with actual traffic data in hand. Set scale-out thresholds based on observed peak demand rather than worst-case assumptions. Build in scale-in aggressiveness, many defaults are too conservative and leave over-provisioned capacity running during low-traffic windows. For Kubernetes, review Horizontal Pod Autoscaler settings per workload and ensure Vertical Pod Autoscaler recommendations are factored into resource requests.
Commitment Management
Develop a rolling commitment strategy: analyze which workloads have run steadily for 90 days or more and convert those to reserved or committed pricing. Review commitments quarterly. Use Savings Plans on AWS for flexibility across instance families, and layer spot or preemptible instances for non-critical, fault-tolerant workloads like batch processing, CI/CD jobs, and data pipelines.
Storage Lifecycle Policies
Most organizations have no enforced policy for what happens to data after it's no longer actively used. Implement tiering: move infrequently accessed data to lower-cost storage classes automatically. Set expiry policies on snapshots. Archive or delete log data beyond a defined retention window. Storage optimization tends to have a quieter ROI than compute, but it accumulates meaningfully at scale.
Workload Scheduling
Not all workloads need to run around the clock. Development and staging environments, scheduled jobs, and batch workloads that run overnight can be stopped during off-hours and weekends. Even simple scheduling automation can cut non-production environment costs by 60–70%.
Cost Optimization Tips for Cloud Infrastructure in DevOps Environments
Optimization works best when it's embedded into the way teams work every day, ideally before infrastructure is deployed at all. The shift-left model means catching cost and performance issues at the design and code review stage, not after they've been running in production for weeks. Here are practical ways engineering teams can make that real.
- Validate and benchmark infrastructure before deploying it. The most effective way to avoid production optimization problems is to not introduce them in the first place. Tools like InfrOS emulate the target environment to verify that generated IaC is actually deployable and benchmark it against performance and cost targets before a single resource is provisioned. This eliminates an entire class of reactive fixes.
- Define resource request standards for Kubernetes. Establish organization-wide defaults for CPU and memory requests and limits. Enforce them through admission policies so under-specified workloads don't make it to production.
- Include cost impact in infrastructure pull requests. Tooling exists to estimate the cost delta of infrastructure changes before they're merged. Building this into CI/CD gives engineers real-time feedback and creates a culture of cost awareness without requiring a separate review process.
- Tag everything from day one. Cost allocation only works if your resources are consistently tagged by environment, team, service, and cost center. Make tagging a deployment requirement, not an afterthought. Untagged resources should fail validation in your IaC pipeline.
- Set up anomaly detection alerts. All major cloud providers offer cost anomaly detection. Enable it, tune the sensitivity, and route alerts to the engineering team that owns the affected resources, not just the FinOps or finance team.
- Review cloud costs in engineering standups. Cost should be a first-class metric alongside latency, error rate, and deployment frequency. A weekly cost review, even a brief one, builds accountability and surfaces waste before it compounds.
- Automate idle resource cleanup. Use policies or tooling to detect and flag, or automatically terminate, resources that have been idle for more than a defined threshold. This applies to stopped instances, unused load balancers, unattached volumes, and stale snapshots.
FAQ
How often should cloud infrastructure cost optimization be performed?
More often than most teams realize. Even if your workloads don't change, your cloud environment does, providers continuously update pricing, introduce new instance types, retire older ones, and launch services that can replace more expensive configurations. What was the optimal setup six months ago may no longer be. Beyond reactive reviews, teams should treat optimization as a continuous background process: weekly cost review cadences, automated anomaly alerts, and tooling that monitors infrastructure drift in near real-time rather than waiting for a quarterly audit to surface waste.
Is infrastructure-level optimization safe for production workloads?
Yes, and the safest way to get there is to validate infrastructure before it reaches production in the first place. Platforms like InfrOS emulate the target environment and benchmark generated IaC against performance and cost targets prior to deployment, so issues are caught at the design stage rather than after they're live. For optimizing existing production workloads, the approach is incremental: test in lower environments first, monitor performance closely after each change, and adjust gradually rather than making sweeping modifications at once.
How does Kubernetes affect cloud infrastructure optimization?
Kubernetes introduces a layer of cost complexity that sits between your applications and the underlying cloud infrastructure. Poorly configured resource requests and limits lead to over-provisioned or under-utilized nodes. Namespace-level cost attribution is often missing by default. Effective cloud infrastructure optimization in Kubernetes environments requires dedicated visibility tools and consistent resource governance policies across clusters.
What metrics matter most for cloud infrastructure cost optimization?
The most actionable metrics are CPU and memory utilization per instance or pod, cost per unit of business output (unit economics), idle resource percentage, commitment coverage ratio, and storage utilization by tier. Tracking these consistently allows teams to prioritize optimization efforts by impact rather than guessing where waste lives.
Can optimization reduce performance risks while lowering costs?
Yes, and this is one of the most misunderstood aspects of infrastructure optimization. Oversized, misconfigured environments often perform worse than well-tuned ones. Fixing autoscaling policies improves responsiveness. Eliminating idle resources reduces noise in monitoring. Proper Kubernetes configuration improves scheduling efficiency. Done right, optimization improves reliability and performance while reducing spend.
.jpg)