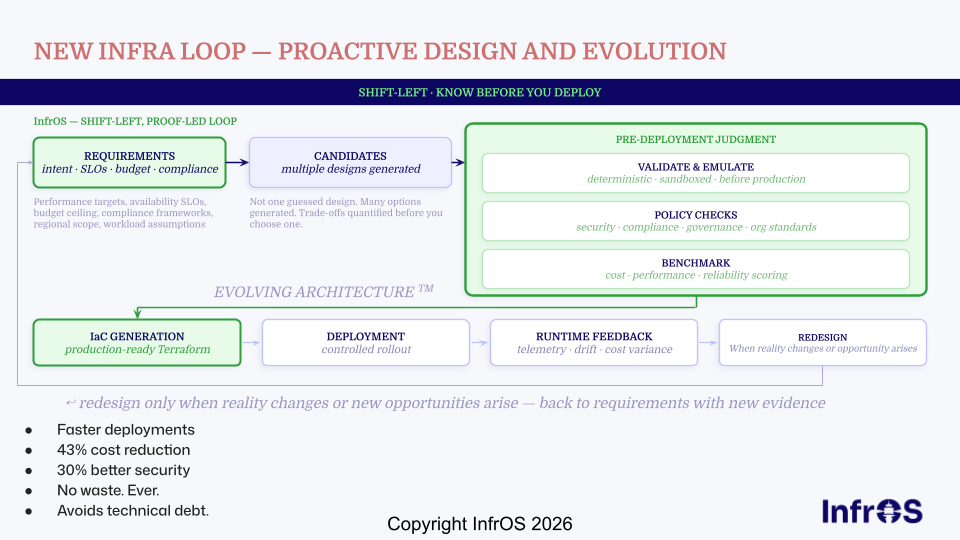
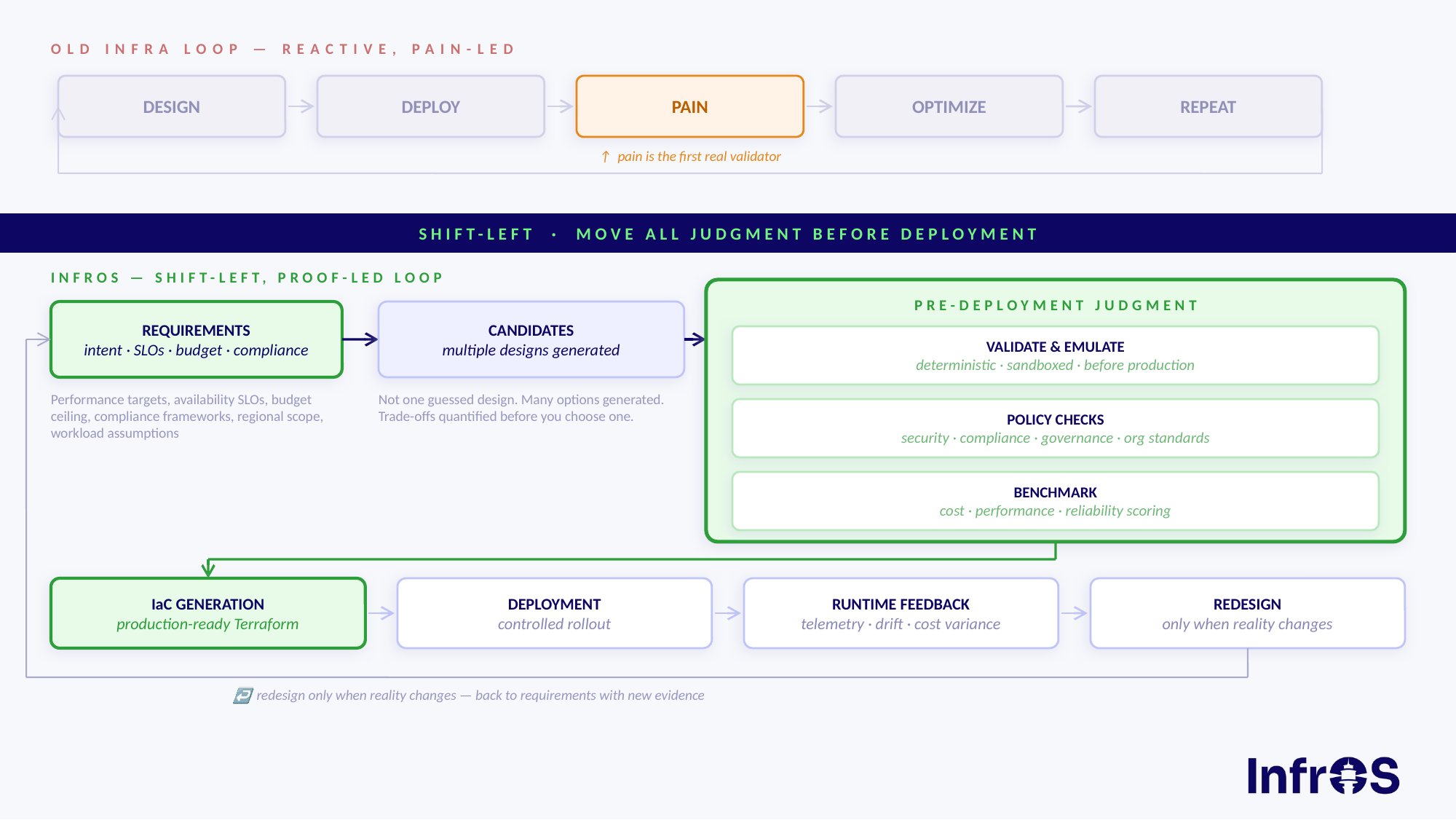
Key Takeaways
- Strategy before servers: A GCP migration strategy starts with workload assessment, dependency mapping, and a separate data migration plan before anything moves.
- Costs go beyond compute: Factor in redesign labor, dual-environment overlap, and egress fees. Build optimization into the plan from day one, not after go-live.
- Business decision first: AI capabilities, cost flexibility, and operational resilience are the real drivers, not just a technical checkbox.
The difference between a smooth cloud migration and a painful one almost always comes down to what happens before anything moves.
Most organizations know they need to get to the cloud. But McKinsey research found that up to 75% of cloud migrations go over budget. The reasons tend to repeat: unclear dependencies, surprise costs, and workloads moved without a plan for how they'd run on the other side. Teams treat migration as a logistics problem when it's really an architecture problem.
A strong Google Cloud Platform (GCP) cloud migration strategy changes this by starting with workload assessment, dependency mapping, and cost modeling before a single server gets touched. When the foundation is right, the execution becomes predictable.
Explore how to plan and execute a Google Cloud Platform migration, what each phase requires, how data is handled, and what shapes the overall cost.
Why Organizations Are Prioritizing Google Cloud Platform Migration
Moving to GCP gives teams access to capabilities that are hard to build and sustain in-house.
AI and data capabilities
Google Cloud's AI and machine learning ecosystem, including BigQuery, Vertex AI, and TPUs, gives organizations a ready-made platform for analytics and ML workloads. For teams training models or deploying generative AI, GCP's infrastructure is already optimized for it.
Cost flexibility
GCP's pay-as-you-go model shifts IT spending from large upfront purchases to operational costs that scale with usage. Sustained-use discounts and committed-use programs add budget predictability on top of that.
Operational resilience and compliance
GCP runs on a globally distributed network with multi-region redundancy and self-healing infrastructure, delivering near-100% uptime for mission-critical services. On the compliance side, default encryption, Zero Trust architecture, and GDPR/HIPAA-aligned certifications make it a fit for regulated industries.
What Defines a Strong GCP Cloud Migration Strategy
A solid GCP migration plan starts with understanding your current environment, defining how each workload should move, and planning for potential risks.
The 6 Rs framework
Not every workload gets the same treatment. The 6 Rs give you a way to categorize each one based on its technical profile and business value.
- Rehost (lift and shift): Move as-is to Compute Engine VMs. Fastest path, fewest cloud-native benefits.
- Replatform (lift and optimize): Move with minor adjustments like shifting a database to Cloud SQL or containerizing for GKE.
- Refactor (re-architect): Rewrite for cloud-native patterns. Highest long-term ROI, biggest upfront effort.
- Repurchase: Replace legacy apps with cloud-based SaaS alternatives.
- Retire: Decommission apps that no longer serve a purpose.
- Retain: Keep certain workloads on-prem due to regulatory, latency, or complexity constraints.
The value of this framework is that it forces a decision for each workload rather than applying a blanket approach.
Related Content: The Top Cloud Cost Cutting Platforms
Workload assessment and dependency mapping
You can't migrate what you don't fully understand.
Automated discovery tools help catalog servers, databases, and infrastructure components, then map their dependencies. That dependency graph is what lets you group workloads into migration waves so interconnected systems move together instead of breaking apart mid-transfer.
Risk planning
Configuration drift, network bottlenecks, and data corruption are the kinds of problems that surface during execution if they aren't identified during planning.
Strong strategies address failure modes upfront. That means building rollback procedures, testing in isolated environments, and assigning priority levels to risks based on severity and likelihood. The goal is to make the final cutover a non-event.
Core Phases of a Google Cloud Migration
A Google Cloud Platform migration follows five phases. Each one builds on the last, and skipping ahead is where most projects start to break down.
Phase 1: Assessment
Start by taking inventory of what you have.
Automated discovery tools like the Google Cloud Migration Center catalog your on-prem assets, including servers, databases, and storage.
From there, benchmark current performance (latency, throughput, error rates) so you have a baseline to measure against. This is also where you build your total cost of ownership (TCO) comparison between your current setup and projected GCP spend.
Important questions to ask:
- What servers, databases, and storage systems are currently in production?
- What does our current environment cost to operate annually?
- Which workloads are candidates for migration and which need to stay on-prem?
Phase 2: Planning and foundation
This phase is about building what Google calls the "Landing Zone," your secure, scalable foundation in GCP. That includes setting up a resource hierarchy (Organization, Folders, Projects), defining IAM roles based on least-privilege access, designing VPC networking, and establishing connectivity to your existing environment through VPN or Cloud Interconnect.
Important questions to ask:
- How should our resource hierarchy be structured for billing and policy control?
- Who needs access to what, and at what permission level?
- How will we maintain connectivity between on-prem and cloud during the transition?
Phase 3: Execution
Move in waves, starting with non-critical applications or pilot workloads to validate the strategy. Use continuous background replication to keep the target environment in sync with the source. Orchestration tools handle launch sequencing, so applications come online in the right order.
Phase 4: Validation
Before the final cutover, test everything in isolated environments. Clone workloads into separate VPCs for functional and performance testing. Verify data integrity through row counts, checksums, and schema checks. Confirm that the target environment meets or exceeds the baseline you set during assessment.
Phase 5: Post-migration optimization
Once workloads are live, the work isn't done.
Rightsize instances based on actual usage data, transition rehosted VMs toward managed services like Cloud Spanner or GKE, and set up continuous governance using tools like Active Assist for ongoing recommendations on cost, security, and performance.
The common mistake is treating Phase 5 as optional. Optimization should be built into the plan from the start, not added on after go-live.
Designing a Successful Cloud Data Migration Strategy
Data migration is not the same as application migration. It needs its own plan, tools, and validation process. A cloud data migration strategy should cover where your data is going, how it gets there without downtime, and how you prove it arrived intact.
Database migration paths
Google Cloud offers managed options depending on your workload type, including:
Choosing the right target service early prevents rework later. Match each database to the service that fits its access patterns and scale requirements.
Minimizing downtime
The Database Migration Service (DMS) uses Change Data Capture (CDC) to replicate data in real time.
Your source database stays fully operational throughout the process. Every insert, update, and deletion gets captured and synced to GCP in the background.
When you're ready, the cutover is a simple repoint of the application to the new cloud endpoint. Schedule the final switch during off-peak hours with a documented rollback plan ready.
Data integrity validation
Google's open-source Data Validation Tool (DVT) automates the comparison between source and target databases. It runs checks at three levels: table level (row counts and filters), column level (schema and data type verification), and row level (hash comparisons for bit-level accuracy).
Catching a data discrepancy after cutover is significantly more expensive than catching it before.
Storage transfer
For non-database data like file systems and object storage, the Storage Transfer Service handles most scenarios.
For massive datasets where bandwidth is a constraint, Google's Transfer Appliance ships to your data center, gets loaded with up to several hundred terabytes, and returns to Google for upload.
Cost Considerations in a GCP Migration Plan
Migration costs don't stop at your monthly cloud bill. A realistic GCP migration plan should account for the full picture: what it takes to get there, what it costs to run, and where the savings actually come from.
Direct migration costs
Infrastructure redesign is often the biggest upfront expense. Dependency mapping, Landing Zone design, and re-architecture work all require skilled labor, and the scope scales directly with the complexity of your environment.
There's also the overlap period. Running dual environments during migration and validation is unavoidable, and it temporarily increases IT spending until the source environment is decommissioned.
Egress fees
Moving data out of an existing cloud provider used to be one of the most painful cost surprises.
Since 2024, Google, AWS, and Microsoft have started waiving egress fees for customers exiting their platforms permanently. The catch: it requires approval and a defined migration window, usually around 60 days.
Google Cloud incentives
Google offers several programs to lower the barrier to entry. The Rapid Migration and Modernization Program (RaMP) provides service credits based on incremental usage, plus funding for specialized partners to help with assessment and roadmap development.
For startups, the Google Cloud for Startups program offers up to $350,000 in credits over two years for companies building AI-focused products.
Long-term optimization
This is where the real savings show up. GCP's pricing model includes several built-in mechanisms for reducing spend over time.
- Sustained-use discounts: Automatic reductions for workloads that run consistently through a billing cycle.
- Committed-use discounts (CUDs): Significant reductions for one or three-year commitments.
- Spot VMs: Steep savings for fault-tolerant batch processing.
- Cold storage tiers: Archive or Coldline pricing for data that's rarely accessed.
Start Your GCP Migration With a Clear Plan
The difference between a migration that delivers value and one that drains budget comes down to preparation.
Most teams know what they want from GCP: better AI capabilities, cost flexibility, and infrastructure that scales without constant manual work. The challenge is getting there without the delays, overruns, and surprises that slow down the majority of migration projects.
InfrOS simplifies GCP migrations using an intelligent cloud infrastructure optimization engine that designs, simulates, and deploys cloud architecture across AWS, Azure, and GCP. It analyzes over 1,000 infrastructure parameters to generate optimized, deployment-ready configurations, cutting months of planning down to days.
Get a migration plan built on optimized, deployment-ready architecture. Book a demo to see how InfrOS gets you there.
FAQs
How long does a typical Google Cloud Platform migration take?
It depends on scope. Small projects with a few apps can wrap up in 2 to 6 weeks. Medium-scale moves typically take 2 to 4 months. Large enterprises with 50+ applications and complex legacy systems often need 6 to 18 months.
What workloads are most complex to migrate to GCP?
Legacy monoliths like large ERP systems and heavily customized Oracle databases. Anything built on proprietary hardware, custom middleware, or with circular dependencies between services will need significant refactoring or a phased wave approach.
How can teams reduce downtime during cloud data migration?
Use continuous replication through the Database Migration Service with Change Data Capture so the source stays live. Test in isolated VPCs before cutover. Schedule the switch during off-peak hours with a documented rollback plan ready.
Are Google Cloud migration tools sufficient for enterprise environments?
Google's native tools (Migration Center, Database Migration Service, Migrate to Virtual Machines) cover most use cases. For multi-cloud or non-standard setups, teams often supplement with third-party options for added flexibility.
When should optimization planning begin in a GCP migration plan?
During assessment, not after go-live. Set performance benchmarks and rightsizing targets before the move. Build cost controls like budget alerts and resource tagging into the Landing Zone from day one.

.jpg)