.jpg)
Key Takeaways
- An enterprise architecture maturity model gives organizations a structured way to assess how well their IT systems support business goals, and a clear path to improve.
- Most companies sit at Stage 2 or 3: they have some architecture documentation and standards, but decisions are still largely reactive, inconsistent, or siloed.
- Each maturity stage demands different actions. Describing the stages without prescribing what to do next is where most guides fall short.
- Cloud architecture decisions should be driven by your maturity level, teams at lower stages need to consolidate and standardize before pursuing complex multi-cloud strategies.
- InfrOS helps engineering teams act on their maturity stage by providing validated, pre-deployment architecture design, so every infrastructure decision is grounded in proven requirements rather than educated guesses.
What Is an Enterprise Architecture Maturity Model
An enterprise architecture maturity model is a structured way to assess how well IT systems and architecture decisions support business goals, and what needs to improve over time.
Organizations don’t manage technology with the same level of consistency or strategic intent. Some make infrastructure decisions reactively, one project at a time. Others operate with documented, governed architecture that guides every major investment. A maturity model maps that progression into defined stages.
Companies use it because “improve IT” is too vague to act on. A maturity model creates a clear baseline: where you are now, what gaps exist, and what actions move you forward. The result is stronger investment planning, better alignment between engineering and leadership, and a more practical roadmap for IT infrastructure transformation.
The 5 Stages of Enterprise Architecture Maturity and What to Do at Each Level
Maturity models vary in their exact terminology, but the underlying progression is consistent. Organizations move from ad hoc, undocumented decisions toward managed, strategically integrated architecture. Here are the five stages, what each one looks like from the inside, and, critically, what to actually do at each level.
Stage 1, Initial: What it looks like + what to do next
At Stage 1, there is no formal architecture practice. Technology decisions are made by individual teams or project managers without coordination. Infrastructure is built to solve immediate problems. Documentation, when it exists, lives in someone's head or a shared drive that no one maintains. Security and compliance are handled reactively. Costs are difficult to explain because no one has full visibility into what's running or why.
This isn't a failure state, it's a starting point that most organizations pass through. The problem is staying here too long.
What to do next: The priority at Stage 1 is visibility, not transformation. Start by taking inventory. Document what systems exist, what they do, who owns them, and what they cost. Don't attempt to redesign anything yet. Establish a small, cross-functional group responsible for architecture decisions, even informally. The goal is to stop making undocumented choices and start building a shared picture of the current state.
Stage 2, Developing: What it looks like + what to do next
At Stage 2, architecture documentation exists but isn't consistently maintained or used. Some teams follow standards; others don't. There may be an architecture function, a team or a few senior engineers with that title, but their influence on day-to-day decisions is limited. Cloud adoption is underway but fragmented: different business units use different providers, different tools, and different conventions. Costs are tracked at the account level but not attributed to teams, services, or business outcomes.
This is where a large proportion of mid-size enterprises sit. The documentation and the intent are there, but enterprise architecture integration into actual decision-making is weak.
What to do next: The priority at Stage 2 is standardization. Define and enforce a baseline set of conventions: naming standards, tagging requirements, approved cloud services, identity and access patterns. These don't need to be perfect, they need to be agreed upon and applied consistently. Introduce architecture review as a lightweight step in project intake, not a gate that slows teams down, but a checkpoint that surfaces alignment issues early. Begin connecting infrastructure spend to business units so cost ownership becomes visible.
Stage 3, Defined: What it looks like + what to do next
At Stage 3, the architecture function has real influence. Standards exist, are documented, and are largely followed. Architecture reviews happen before significant projects begin. There is a current-state inventory that's reasonably accurate. Cloud enterprise architecture decisions are made with awareness of the broader environment rather than in isolation. Compliance and security requirements are mapped to infrastructure, though enforcement may still be partially manual.
The main gap at Stage 3 is execution. Architecture is documented, but environments still drift as teams move quickly and changes bypass review.
What to do next: The priority at Stage 3 is closing the gap between design and reality. This means investing in tooling that detects drift, enforces policy in pipelines rather than after deployment, and connects architecture decisions to infrastructure code. Shift architecture review earlier, into the design and planning phase, not just the approval phase. Begin measuring architecture outcomes: deployment frequency, incident rates tied to architecture decisions, cost per service. These metrics build the business case for the next stage of investment.
Stage 4, Managed: What it looks like + what to do next
At Stage 4, architecture is quantitatively managed. Decisions are informed by data: utilization metrics, cost-per-unit economics, performance benchmarks, compliance dashboards. The gap between intended and actual architecture is tracked and systematically reduced. Enterprise architecture integration is real, business strategy and technology strategy are explicitly connected, and architecture decisions reference business outcomes rather than just technical preferences.
Cloud architecture at this stage is intentional. Multi-cloud or hybrid environments are governed deliberately, and infrastructure transformation projects begin with validated target architectures.
What to do next: The priority at Stage 4 is continuous improvement and automation. Architecture governance should be embedded in CI/CD pipelines so enforcement is automatic rather than manual. Begin building predictive capability: using cost and performance data to model the impact of architectural changes before they're made. Platforms like InfrOS operate in this mode, generating validated, benchmarked architecture designs before deployment so that every infrastructure change has a proven outcome attached to it. Teams at Stage 4 are ready to use this kind of tooling at full value.
Stage 5, Optimizing: What it looks like + what to do next
At Stage 5, architecture is self-improving. The organization treats its IT environment as a continuously evolving system: runtime feedback loops into the next design cycle, cost and performance data drives automated optimization recommendations, and architecture decisions are made with quantified confidence rather than professional judgment alone. Business and technology planning are genuinely integrated, the architecture roadmap and the business strategy are produced together, not reconciled after the fact.
Very few organizations operate consistently at Stage 5. It’s best treated as a direction rather than a fixed destination.
What to do next: The work at Stage 5 is sustaining and scaling. Governance models that work for a 200-person engineering team may not hold at 2,000. Architecture practices need to evolve as the organization grows, acquires companies, or expands into new markets. Invest in architecture enablement, tools, documentation, and training that let teams self-serve within well-defined guardrails rather than routing everything through a central review function. The goal is an architecture practice that scales with the business without becoming a bottleneck.
The Criteria Used to Assess EA Maturity
Moving from a self-assessment to a reliable maturity score requires evaluating specific dimensions of the architecture practice. These are the areas that consistently distinguish lower-maturity organizations from higher-maturity ones.
Technology use. How systematically is technology selected, managed, and retired? Low-maturity organizations accumulate tools without strategic intent. High-maturity organizations maintain a rationalized technology portfolio, make explicit decisions about approved services, and decommission what no longer serves a purpose.
Data quality and currency. Architecture documentation is only useful if it reflects reality. Assess how often your architecture inventory is updated, who owns it, and how closely it matches what's actually running in production. Stale documentation is a Stage 2 characteristic; continuously maintained, system-integrated inventories are Stage 4.
Team participation. Architecture maturity is not a property of the architecture team alone, it's a property of how the entire engineering organization makes decisions. How often are architecture considerations surfaced in team-level planning? How much do product and engineering teams understand about the architecture standards that apply to their work?
How architecture decisions are shared. At low maturity, architecture decisions live in documents that few people read. At high maturity, they're embedded in tools, pipelines, and approved patterns that developers encounter naturally as they work. Decision visibility and accessibility are strong signals of where an organization sits on the scale.
Cost alignment. Can your organization trace infrastructure spend to specific business outcomes? The ability to answer questions like "what does it cost us to serve one customer" or "what did this architectural change cost us in production" is a reliable indicator of maturity. Organizations without tagging standards, cost attribution, or unit economics tracking tend to cluster at Stages 1–2.
Security and compliance. How are security requirements enforced, through manual review, automated policy checks, or by design? At lower maturity, security is a layer applied after the fact. At higher maturity, it's a constraint incorporated at the design stage, validated before deployment, and continuously monitored in production.
How EA Maturity Connects to Cloud Architecture and IT Transformation
Your position on the maturity scale has direct, practical consequences for how you should approach cloud enterprise architecture decisions and IT infrastructure transformation.
Low-maturity teams, Stage 1 and 2, are operating reactively. Architecture decisions get made in the context of individual projects, without visibility into the broader environment. When these teams attempt complex cloud migrations or multi-cloud strategies, they consistently encounter the same problems: inconsistent environments, cost overruns, compliance gaps, and rework. The issue isn't cloud strategy, it's that the foundational architecture practice isn't ready to support it. Attempting an IT infrastructure transformation before reaching at least Stage 3 is a predictable source of expensive failure.
Mid-maturity teams, Stage 3, have the standards and documentation to support cloud enterprise architecture decisions, but they often lack the enforcement mechanisms to keep those decisions consistent across teams and over time. Cloud environments at this stage tend to drift: what was designed and what's running diverge as teams move fast and bypass review processes. The transformation work at Stage 3 is connecting architecture intent to actual infrastructure, through policy-as-code, IaC validation, and tooling that surfaces drift automatically.
High-maturity teams, Stage 4 and 5, design first and deploy with confidence. This is where enterprise architecture integration becomes a genuine competitive advantage rather than an overhead cost. Architecture decisions are validated before deployment, grounded in benchmarked data rather than estimates, and connected to measurable business outcomes. IT infrastructure transformation at this level is predictable: timelines hold, costs come in as projected, and post-deployment surprises are the exception rather than the rule.
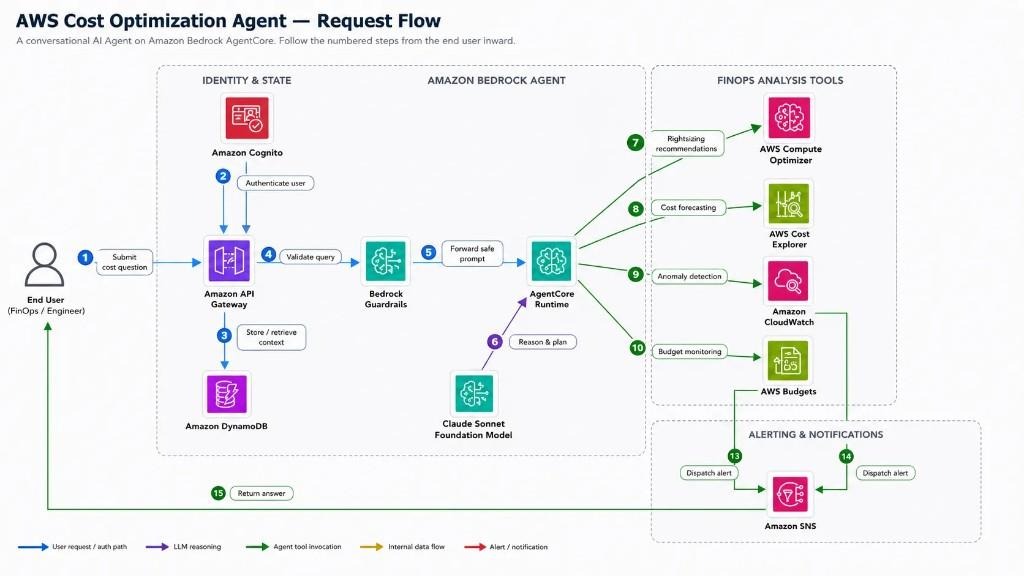
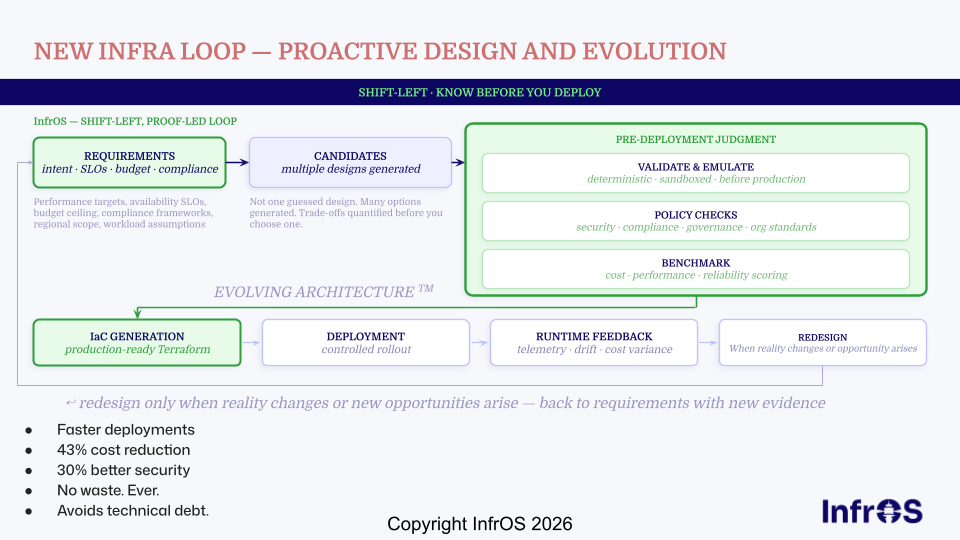
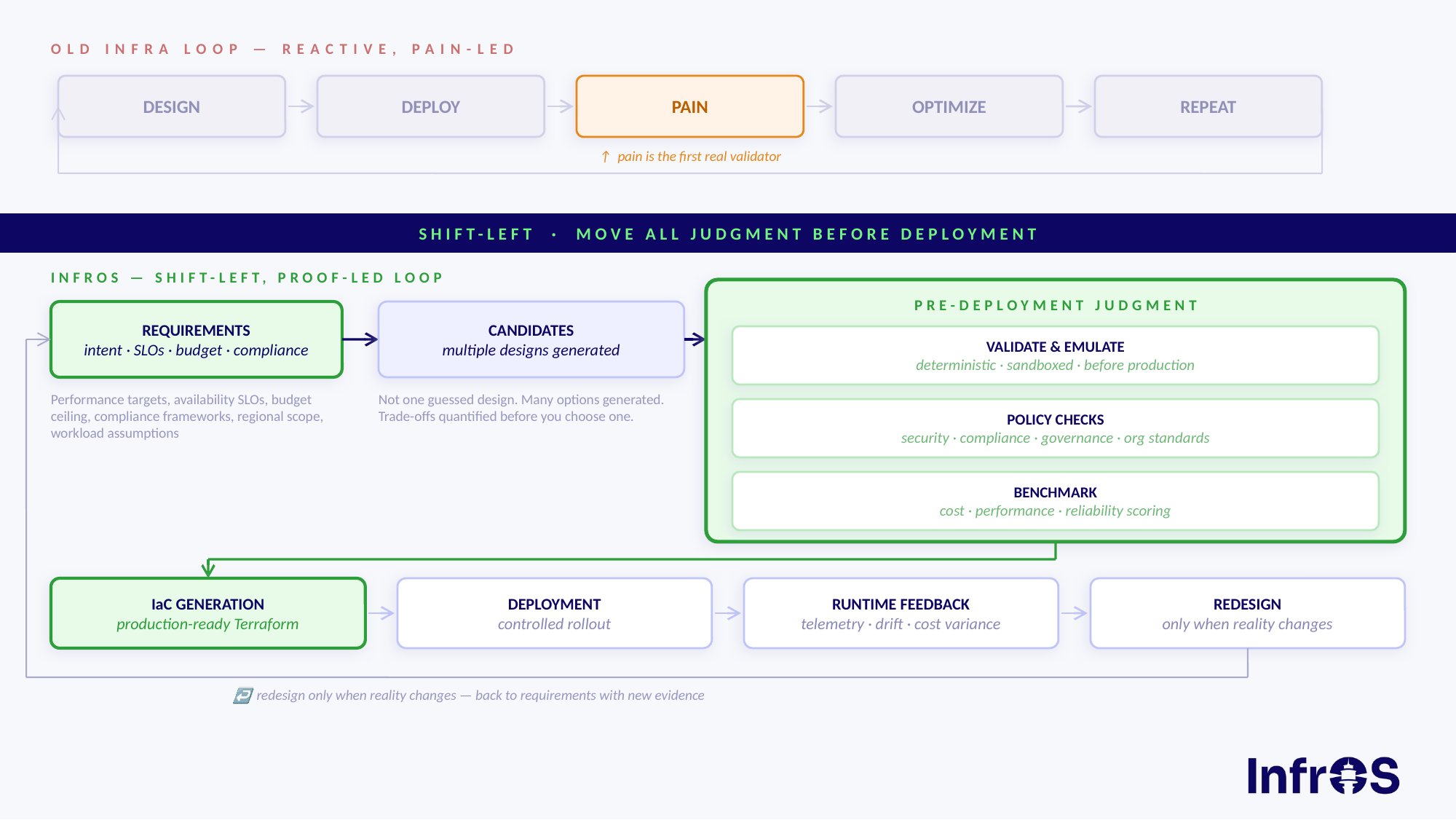
InfrOS is built for teams making this shift. By emulating architecture candidates in a sandboxed environment before any resources are provisioned, it gives engineering teams the validated design foundation that Stage 4 and 5 maturity requires, and accelerates the path for Stage 3 teams ready to close the gap between design and deployment. Whether you're planning a cloud migration or building toward scalable cloud infrastructure, the architecture decisions you make before deployment determine the outcomes you get in production.
Organizations that treat architecture as a design discipline, not just documentation, typically spend less, deploy faster, and avoid more post-deployment remediation. Maturity measures how consistently they can do that.
FAQ
What is the difference between an EA maturity model and an EA framework?
A framework such as TOGAF or Zachman outlines how an enterprise architecture practice is structured and documented. A maturity model measures how consistently those practices are applied and how developed they are. Frameworks define the approach; maturity models show how effectively that approach is working.
How long does it take to move from one maturity stage to the next?
Most organizations move between maturity stages in six to twenty-four months depending on size, leadership support, and available tooling. Standardizing processes usually happens faster. Moving into higher maturity levels takes longer because it often requires automation, stronger governance, and closer alignment between architecture and business planning.
How does EA maturity affect cloud architecture decisions?
At lower maturity levels, cloud architecture decisions are usually reactive and disconnected across teams. At higher maturity levels, decisions are planned against documented standards, validated before deployment, and tied to measurable business outcomes. That leads to more predictable costs, stronger governance, and fewer infrastructure changes after launch.
Which model works best for companies undergoing IT infrastructure transformation?
For teams in active IT infrastructure transformation, models such as the US government Architecture Maturity Model or Gartner ITScore provide useful structure. The most important factor is consistency: assess your current state, identify the biggest gaps, and use that information to prioritize architecture decisions before major infrastructure investments.